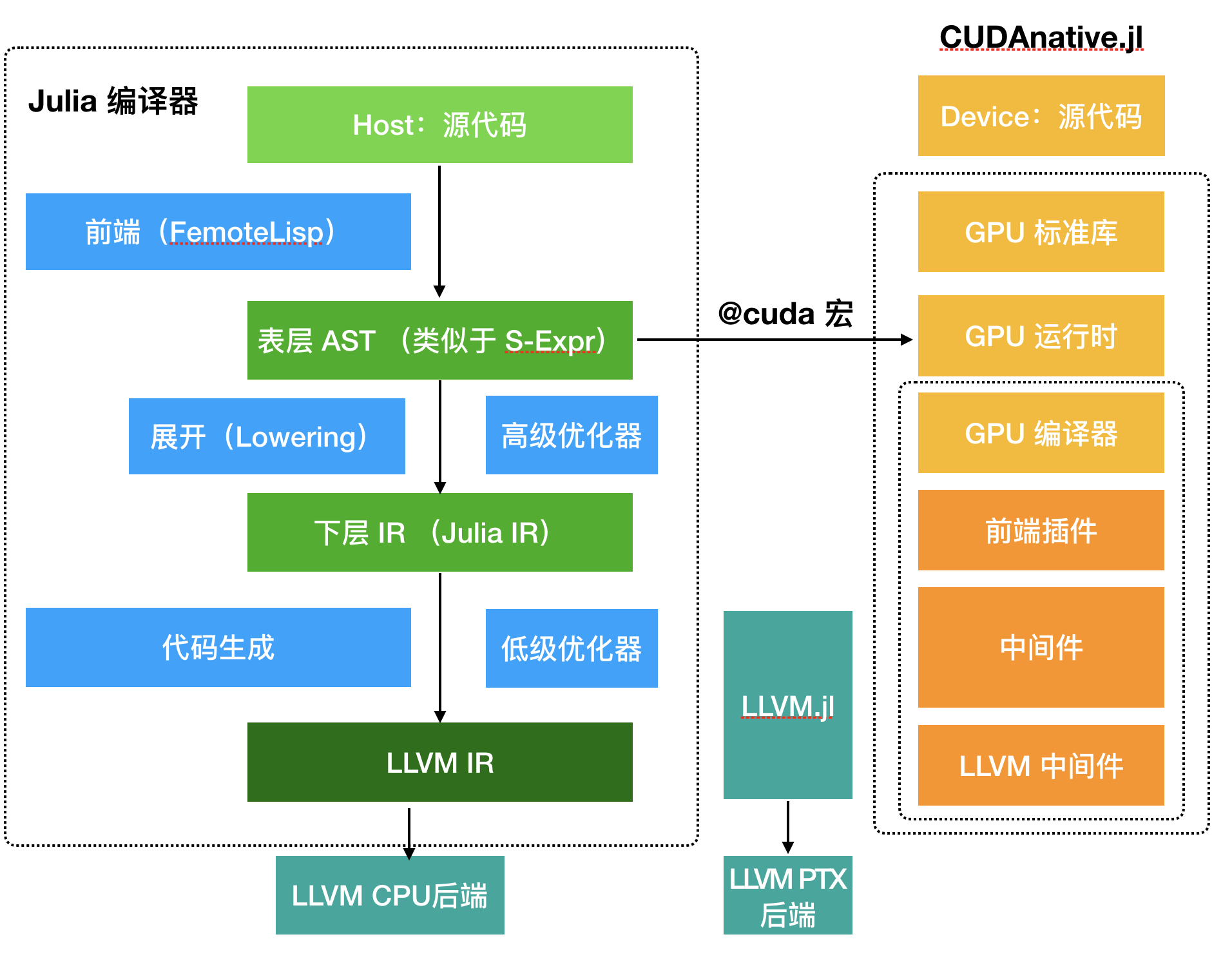
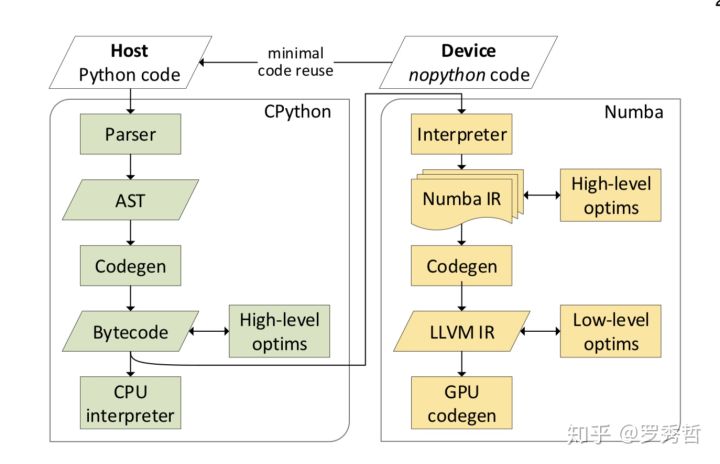
代码执行上的效率还是很难达到的,目前Julia的BLAS库还是调的Fortran代码,虽然现在社区里也有人正在研究用纯Julia实现BLAS,但感觉一时半会还是赶不上Fortran优化多年的成熟库,对这块感兴趣可以关注一下官方slack的#linear-algebra频道。 如果考虑开发效率,Julia有着显著的优势,在实际开发中,对于效率要求很高的部分,可以用Fortran实现,然后从Julia调Fortran。由于Julia调Fortran的FFI非常简洁,所以这里产生的two language problem不是那么的明显。
The thing I wish people understood about Python performance is that the difficulties come from Python’s extremely rich object model, not from anything about its dynamic scopes or dynamic types. The problem is that every operation in Python will typically have multiple points at which the user can override the behavior, and these features are used, often very extensively. Some examples are inspecting the locals of a frame after the frame has exited, mutating functions in-place, or even something as banal as overriding isinstance. "
Sure you can make Python fast in some cases where you use a small subset of the language. However, Python as a whole is extremely difficult to make fast because of the incredible freedom you have. The “compiler” can assume very little, so it is difficult to generate efficient code. Just consider the incredible amount of time and money that has been spent on trying to make it faster and the relatively mediocre success it has had (Pyston, Numba, PyPy etc).