利用 CSV.write(“sub.csv”,df) 将DataFrame数据(含中文字符)写入csv文件,用Excel打开后出现乱码。
解决办法:用记事本打开csv文件、保存,再用Excel打开就没有问题了。
网上说根本解决方法是在生成CSV时设置BOM头,请问在Julia中该如何设置呢?谢谢!
利用 CSV.write(“sub.csv”,df) 将DataFrame数据(含中文字符)写入csv文件,用Excel打开后出现乱码。
解决办法:用记事本打开csv文件、保存,再用Excel打开就没有问题了。
网上说根本解决方法是在生成CSV时设置BOM头,请问在Julia中该如何设置呢?谢谢!
这个是 Excel 的问题, Excel 不能用 UTF8 编码,有 BOM 头好像也不行。
嗯,谢谢,那就只能先暴力打开再保存了。
既然你说它认BOM,我们加上不就完了…
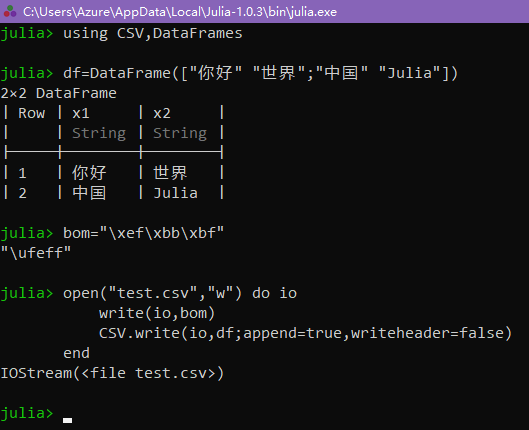
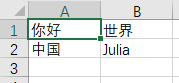
想要表头的话就改成writeheader=true
所以说建议看一下字符编码相关的知识,不然每次你都要卡在这…
Excel以及大部分微软家的软件出于某种兼容性考虑,看到CSV没有BOM的时候会默认是本地legacy encoding(GBK)。如果你细心的话会看到另存为CSV的时候有一项CSV UTF-8(逗号分隔)的格式,可以证实这个说法。
我不知道为什么你说Excel不认BOM,但是我猜测你没有使用append=true参数,你看一下CSV.write的帮助,如果不加这个的话IO会被truncate掉,所以你先前写进去的BOM就丢了。你重新打开文件read一下就会发现这一点。另外append=true的时候会默认writeheader=false。
牛!谢谢,谢谢,谢谢!
所以在CSV.read读列名是中文的csv文件时除了通过记事本打开再保存来解决中文字符乱码吗
请问你想表达什么?
CSV.jl和Excel在正确使用的前提下都不应该有乱码问题,你可以仔细查看前面的讨论