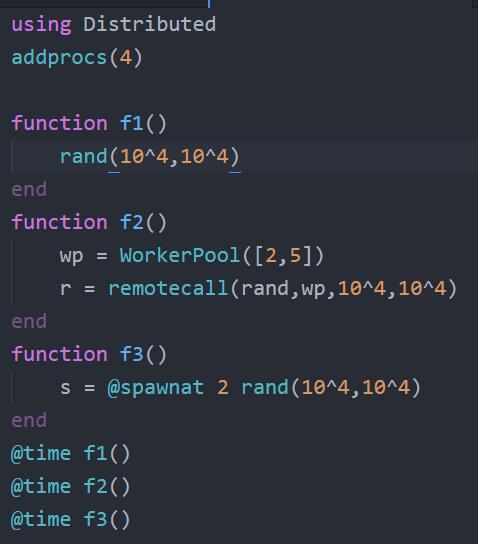
我测试了一下并行计算的速度
addprocs(4)
function1 → rand(10^4,10^4)
function2 → wp = WorkerPool([2,5])
r = remotecall(r .+ 1,wp,10^4,10^4)
function3 → s = @spawnat 2 rand(10^4,10^4)
第一次编译的速度是
1:0.6s
2:0.7s
3: 0.8s
还有第二个案例
首先新建了一个 rand(10^4,10^4)的矩阵
function1 → r = r .+ 1
function2 → s = @spawn 1 .+ r
function3 → s = @spawnat 2 r .+ 1
第一次编译的速度是
怎么越并行越慢了?是什么地方出错了吗
Roger
2
贴一下你是如何测试时间的?你贴的这些代码无法获得你给的这些结果。
Roger
4
这是正常的,你创建新的进程需要时间。所以每个进程的创建都有一个常数的overhead,你现在的这个任务本身耗时很少。
只有当你的程序本身需要很长的时间,使得这个overhead微不足道以后,并行才有明显的优势。你可以试试在remote端进行一些比较耗时的操作,就会观察到并行的越多越快。
哦哦,我运行这种任务的时候用cuArrays会比没用的时候多花了十倍,也是这个意思吗?
Roger
6
类似,但是原因不完全一样,CUDA除了有spawn的overhead还有CUDA会拷贝你RAM里的数据到GPU memory里去,这个是非常耗时的。所以也有常数的overhead。
总之不要去用这种比较重的模型做本身就非常快的计算。如果想要轻量级的并行,可以考虑threading。