我现在有一个文本文件 1.txt,其内容格式如下:
*ABCDE
1, 0, 0, 0
2, 1, 0, 0
3, 1, 0, 1
*xyz
4, 0, 0, 1
5, 1, 5, 0
****xyz****
问题:我现在想要读取这个文件中的数字行,以 * 开头的行自动略过,最好是能把读进来的数字存到一个矩阵中。
请问大家有什么办法呢?![]()
1.txt,其内容格式如下:*ABCDE
1, 0, 0, 0
2, 1, 0, 0
3, 1, 0, 1
*xyz
4, 0, 0, 1
5, 1, 5, 0
****xyz****
* 开头的行自动略过,最好是能把读进来的数字存到一个矩阵中。请问大家有什么办法呢?![]()
readlines 全读取进来,然后 filter 一下?
文件太大就 open之后,弄个循环 readline 读一行处理一行。
具体的可以去看文档,自带的标准库DelimitedFiles应该也是一样的效果。
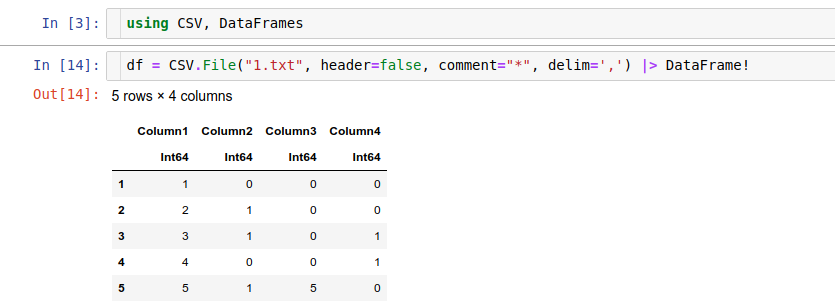
using CSV, DataFrames
df = CSV.File("1.txt", header=false, comment="*", delim=',') |> DataFrame!
补充楼上。
使用标准库 using DelimitedFiles 的 readdlm 函数
readdlm(source, delim::AbstractChar, T::Type, eol::AbstractChar; header=false, skipstart=0, skipblanks=true, use_mmap, quotes=true, dims, comments=false, comment_char='#')
julia> using DelimitedFiles
julia> readdlm("1.txt", ',', Int; comments=true, comment_char='*')
5×4 Array{Int64,2}:
1 0 0 0
2 1 0 0
3 1 0 1
4 0 0 1
5 1 5 0
十分感谢![]()