由于julia的索引是按字节来的,对中文支持不好,现在我只能用split分成列表再索引,有什么好的方法吗?
Julia 的字符串是可迭代的,可以用 for 循环来迭代,循环过程中不会出现无效索引。如果你确实要用索引,firstindex、lastindex、thisind、prevind 和 nextind 是一些相关的函数,它们以及字符串的文档见 这里。
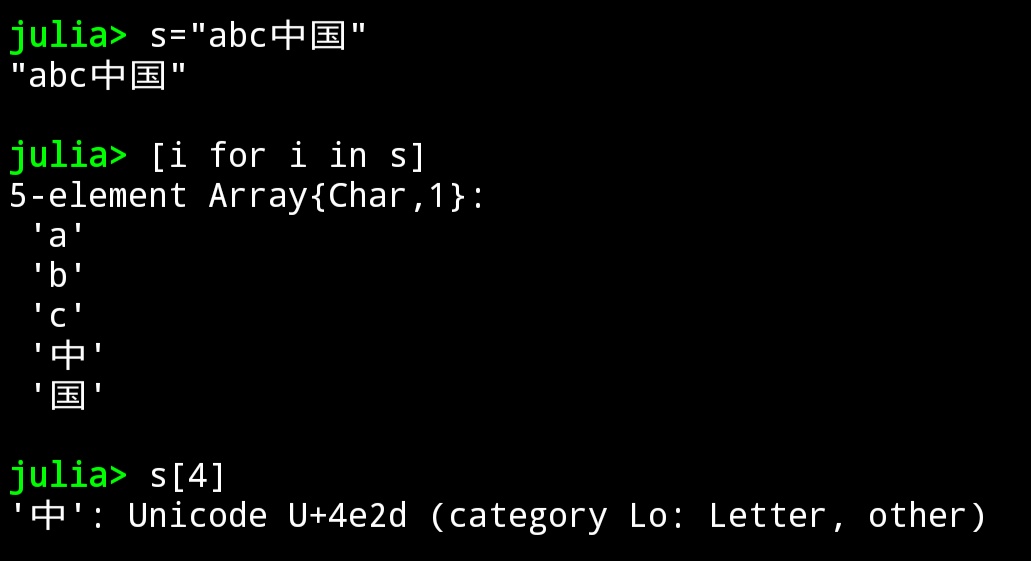
您来个 s[5] 试试
这。。尬了
目测只能用for循环了![]()
这差不多是个 feature
从概念上讲,字符串是从索引到字符的 部分函数 :对于某些索引值,它不返回字符值,而是引发异常。这允许通过编码表示形式的字节索引来实现高效的字符串索引,而不是通过字符索引——它不能简单高效地实现可变宽度的 Unicode 字符串编码。
在 UTF-8 中,ASCII 字符——小于 0x80(128) 的那些——如它们在 ASCII 中一样使用单字节编码;而 0x80 及以上的字符使用最多 4 个字节编码。这意味着并非每个索引到 UTF-8 字符串的字节都必须是一个字符的有效索引。如果在这种无效字节索引处索引字符串,将会报错
—— Unicode 和 UTF-8 | 字符串 · Julia中文文档
一般来说 for 就能解决迭代的问题
你应该是想要 python 那样的索引值对应大家理解的一个 “字符”
julia> s = "字符串与 unicode"
"字符串与 unicode"
julia> length(s)
12
julia> for i in 1:length(s)
idx = nextind(s, 0, i)
println(s[idx])
end
字
符
串
与
u
n
i
c
o
d
e
julia>
另外你其实想要的是 graphemes
julia> using Unicode
julia> s = "字符串与 unicode"
"字符串与 unicode"
julia> for g in graphemes(s)
println(g)
end
字
符
串
与
u
n
i
c
o
d
e
julia>
stackoverflow 也指出了,问题根本所在是 UTF8 变长,你也可以通过 JuliaStrings/LegacyStrings.jl: Legacy Unicode string types 包换一个定长的编码,这样迭代来就简单一些。
ref:
这事深究得怪人类语言多种多样以及 unicode 水太深,除了 perl 能吊打其他语言外,剩下的都半斤八两: 其实你并不懂 Unicode - 知乎
稍微测试了下
第一个印度语的的例子 julia 的长度是对的;第二个下划线就不对了,多了一倍。
不过还好,自己搞不定就用现成的,julia 用了 PCRE,这样通过 perl 的正则就能处理这些问题了。
试了下通过 match(r"\X", s) 可以匹配到 肉眼可见的/大家默认的/所谓的“字符”,即 grapheme。
3 个赞
利用 nextind 和 getindex 两个函数就可以实现。n 为字符串 s 中的第 n 个字符。
getindex(s,nextind(s,0,n))
2 个赞