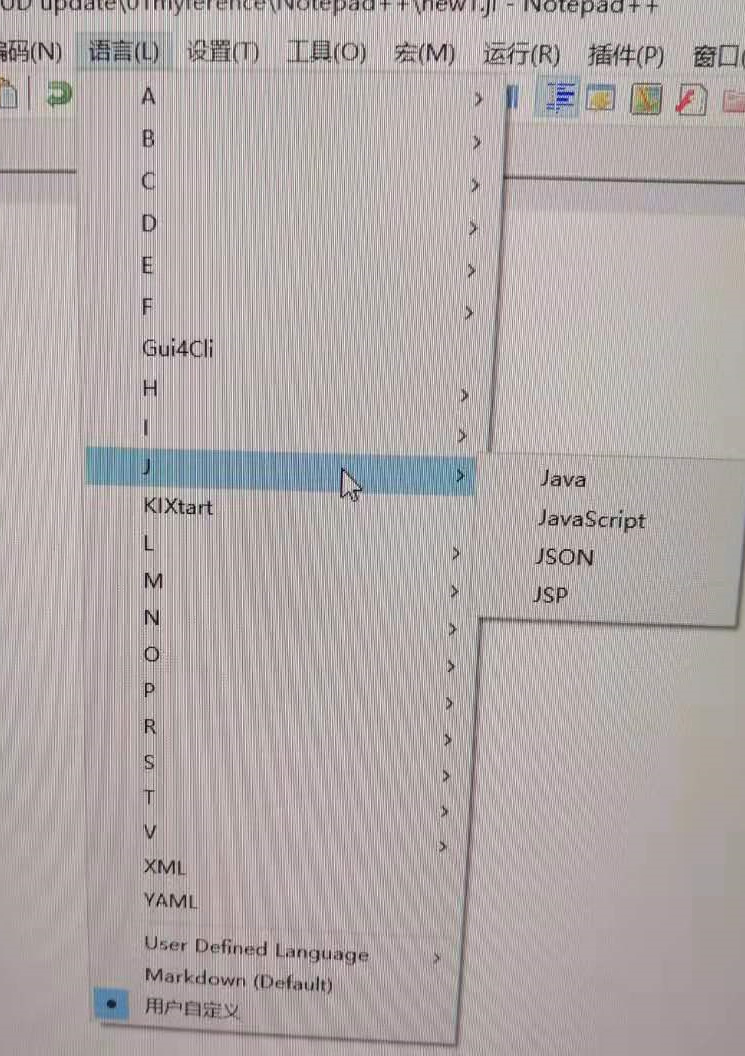
我用readlines读取其它软件生成的DAT格式数据文档,读出来的汉字都是Unit8格式,如下图所示
![]()
在Atom编程界面内如何显示为汉字?我没有找到Unit8到Unicode转化的方法。
在Atom中敲汉字,汉字就可以正确显示,汉字格式是Unicode格式,如下图所示
![]()
求各位大神答疑解惑!
我用readlines读取其它软件生成的DAT格式数据文档,读出来的汉字都是Unit8格式,如下图所示
![]()
在Atom编程界面内如何显示为汉字?我没有找到Unit8到Unicode转化的方法。
在Atom中敲汉字,汉字就可以正确显示,汉字格式是Unicode格式,如下图所示
![]()
求各位大神答疑解惑!
那你的 DAT 格式文件能用记事本打开正常显示么?
我用 v1.0.5 测试是没问题的。
2692.txt UTF-8 无 BOM CRLF
中文
汉字
Julia
julia> readlines("2692.txt")
3-element Array{String,1}:
"中文"
"汉字"
"Julia"
julia> read("2692.txt")
21-element Array{UInt8,1}:
0xe4
0xb8
0xad
0xe6
0x96
...
感谢您的回答!
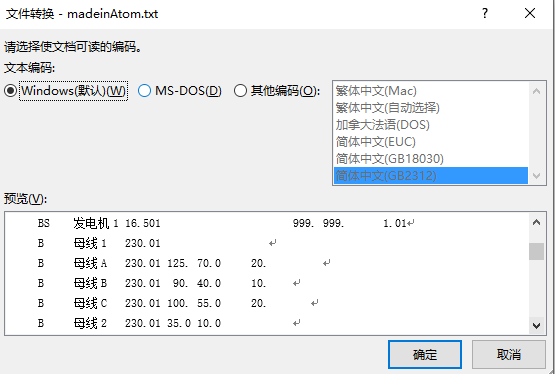
我的DAT文档用记事本打开是正常的,如下图
![]()
用Atom打开,在Atom界面显示就已经不对了,请见下图
![]()
我查了下,编程问号形式之后,它已经失去所有汉字信息了
读取上面文件
![]()
显示结果:
![]()
另外,我尝试用word打开
你的txt文件里面数据是在记事本里面输入的还是在IDE客户端输入的呢?
还有一个现象,我直接新建一个.txt文件或者.dat文件(直接把.txt后缀改成.dat),用Atom读汉字就是上面显示那样。但是我在Atom里把文件打开,复制记事本打开的内容粘贴到Atom界面里面的文件夹里,读取的汉字就是正确的。
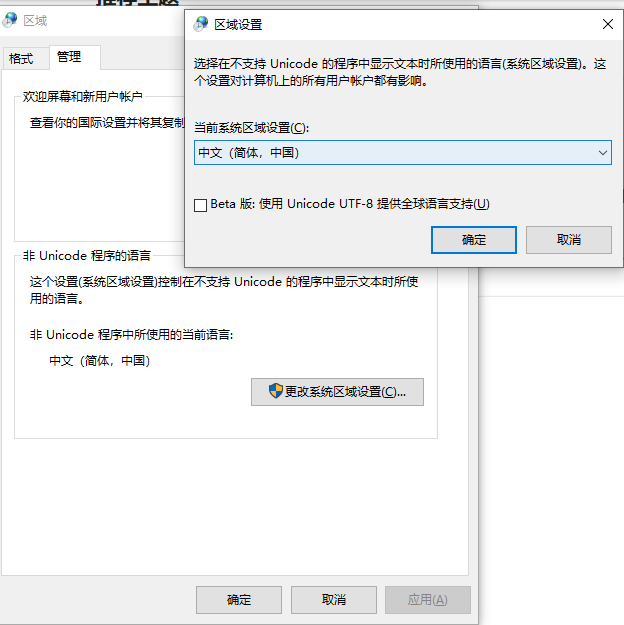
附上我的系统语言设置:
你用word打开时他识别为了 GB2312,说明你输出时,编码选的不对。
atom 右下角也会显示当前的编码,你改成 GB2312 估计就能正常显示了。
记事本另存为时可以选编码。写入文本时都用 UTF-8 就不会有问题。
谢谢大佬!!!
真的太6了![]()
![]()
![]()
![]()
大神,我还想问一下,我读入的数据和你的不一样
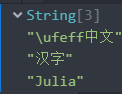
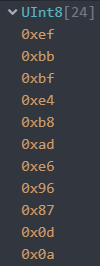
那个是 BOM
务必保存为 UTF-8 without BOM,也就是倒数第二个,不要选最后一个。
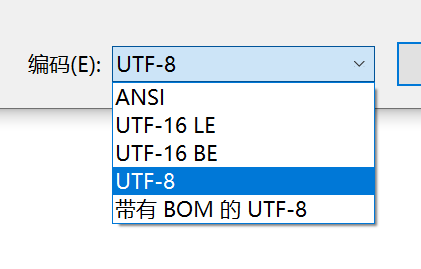
平时用 Notepad++ 吧,就没这么多事。默认 LF + UTF-8 without BOM。
打开各种格式的文件也能正确显示。
嗯嗯好的!
我使用的就是UTF-8,自带BOM,知乎上面说是windows电脑的问题,不带BOM其实应该才是标准的。
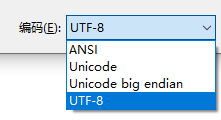
另外想问的就是,如果ANSI编码读进去,这个Uint8类型还可以还原成汉字吗?![]()
![]()
估计是你系统版本的问题,新一点的 win10 记事本有这个选项(我是1909)。
用 notepad++ 吧。
哈哈好嘞![]()
理论上标准的Unicode字节流开头需要有BOM,可惜是微软的一厢情愿,开源软件世界不吃这套。
如果你不带BOM,使用微软系产品打开容易出现问题,比如无法识别文件编码。
好嘞![]()
GB18030也是python在win上日经问题。。