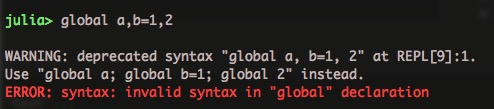
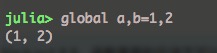
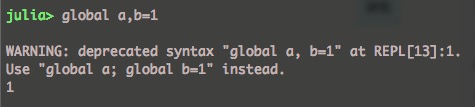
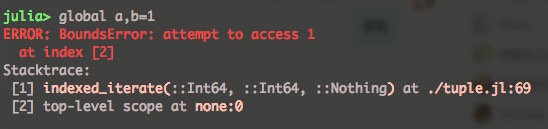
数组
a = Int[1,2,3]
b = String["asd","a"]
会产生什么问题呢?Roger 说 Julia 是没有 Lexer 的,对于单纯的词法分析,如果有
Int[1] # 一个Int类型的,只有一个值为1的元素的数组
int[1] # 名为 int 的数组取1的下标
同理还有 这样的……
a[1,2]
表示第一行第二个元素
julia> r=[1 2 3;4 5 6]
2×3 Array{Int64,2}:
1 2 3
4 5 6
julia> r[1,2]
2
julia> Int[1,2]
2-element Array{Int64,1}:
1
2
就不能简单分辨到底是指的 某个类型的数组 还是 某个变量的数组下标。必须根据上下文来判断。(Julia以及绝大部分的语言都没有什么所谓 类型强制要求大写 的……)
另外还有冒号
冒号有表示 quote 语句,在数组中又可以表示范围
于是在解析语法过程这就很糟心了……由于运算符优先级的问题
a = [:A :B]
这个 a 被当作了 [: (A:B)],
总之 Array 的语法解析比较复杂,咱又得 fix bug
支持的语法
还有这个
1[1]
好神奇……
然后经过这些天的努力……Fix了好多Array,我怀疑自己要精通 Julia Array 的构造了……
可以作为被赋值的表达式:
[1]
[1,2,3]
[1;2;3]
[[1,2,3];[4,5,6]]
6-element Array{Int64,1}:
1
2
3
4
5
6
二维数组
# 空格分割表示创建二维数组……
[1 2 3]
# 错误用法
# [1,5; 3,3 ; 4,4;]
# 应为:
julia> [1 5; 3 3 ; 4 4;]
3×2 Array{Int64,2}:
1 5
3 3
4 4
# 错误用法2
# [1,3;4]
# [1,3;4;]
范围符号 (冒号)
[1:5;] # 表示[1,2,3,4,5]
julia> [1:5]
1-element Array{UnitRange{Int64},1}:
1:5
[1 2; 3 4]
2×2 Array{Int64,2}:
1 2
3 4
有关 end 下标
由于julia索引是1开始的,所以 end 其实也就等于数组的长度的值
a=[1, 2, 3,4]
a[1:end]
a[end:1]
a[end-1]
a[Int(0.5end)]
(最后一个谁真要这么写迟早被打死)