我对比了一下几种常见的科学计算C, Python, Mathematica, Matlab的语言的速度. (顺便也可以给还没入坑的人吹一波Julia)
代码是判断1-500,000的质数(不要吐槽算法,我故意用了个慢的照顾一下C), 考虑到不同语言调用系统I/O可能方式不同,所以都没加输出.
同时还想问下这个Julia的速度/执行效率正常吗?
测试都是单核的, CPU是Intel Xeon E5-1603v3@2.8GHz 以下是结果:
1.C:(GCC: 5.4.0)
Code:
#include <stdio.h>
#define MAX 500000
int prime(int n);
int prime(int n) {
int i;
for (i= 2; i < n; i++)
if (n % i == 0)
return 0;
return 1;
}
int main() {
int i;
for (i= 2; i <= MAX; i++) prime(i);
return 0;
}
用时:

2.Julia:(0.6.4)
Code:
function testp(x)
for i=2:x-1
if x%i==0
return 0
end
end
return 1
end
for i=1:500000
testp(i)
end
用时:
![]()
3.Matlab(R2018a)
Code:
function re=testp(x)
for i=2:x-1
if mod(x,i)==0
re=0;
return
end
end
re=1;
return;
end
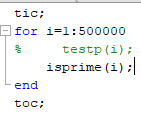
tic;
for i=1:500000
testp(i);
end
toc;
用时:
![]()
如果用Matlab内置函数isprime(x):
![]()
4.Mathematica(11.2)
Code:
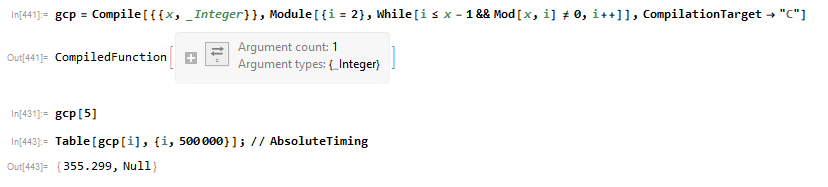
gcp = Compile[{{x, _Integer}},Module[{i = 2}, While[i <= x - 1 && Mod[x, i] != 0, i++]], CompilationTarget -> "C"]
Table[gcp[i], {i, 500000}]; // AbsoluteTiming
用时:
5.Python (3.5.2)
Code:
def testp(x):
for i in range(2,x):
if(x%i==0):
return 0;
return 1;
for i in range(1,500000):
testp(i)
用时:

结论: C(35.6s)> Julia(112.9s) > Matlab(232s)> Mathematica(355.2s)>Python(16min57s).
C在执行效率方面还是无与伦比啊,不得不说"你爸爸还是你爸爸". Julia虽然居于第二,但是并没我之前想象中的可以和C的速度比拟. 不知道是不是我的姿势水平太低,能不能继续提升Julia的效率. Mathematica 我在调用函数前预先compile成了C的代码,所以讲道理不是Wolfram language 的速度, 如果不compile,根本算不出来…![]() (不过我代码就一行啊
(不过我代码就一行啊 ![]() )Python有点慢的令人发指
)Python有点慢的令人发指 ![]() .
.
FYI
内置函数比较:
1.Mathematica的内置函数:
Table[PrimeQ[i], {i, 500000}]; // AbsoluteTiming

2.Matlab内置函数isprime(x):
![]()
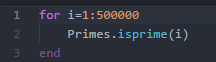
3.Julia 内置函数Primes.isprime(x):
![]()
Julia prevails!