
- ReinforcementLearning.jl 小星星先走一波

- 【预告】欢迎周六晚上来听我的直播噢~ Julia中文社区线上会议开始报名 - #10,来自 Jun
- 以下是我本次报告准备的内容,欢迎回复本帖
提供反馈意见吐槽。
强化学习领域在最近几年里发展得相当快,相关的工具库也如雨后春笋般纷纷涌现。就目前来说,这些库主要以Python语言为主,大多基于PyTorch或TensorFlow而开发,这里主要介绍一个用Julia语言编写的强化学习库:ReinforcementLearning.jl,我们将重点阐述其背后的设计思想,讨论Julia这门语言所带来的编程优势,并结合当前强化学习领域的发展趋势反思如何才能实现一个更好的强化学习库。
背景
时间回到两年前,当时强化学习的库屈指可数,偶然的一天,我听了田渊栋的一个分享,介绍他们团队开发的一个强化学习的库:ELF。印象最深的部分是自然是他们用这个库复现了 AlphaZero [1] 算法,除此之外,当时最强烈的一个感受是,代码库太复杂了…如果一个这么优秀的算法却很少有人能复现和使用,那就太可惜了。当时有一页slide很有意思,介绍了深入掌握强化学习的四要素:
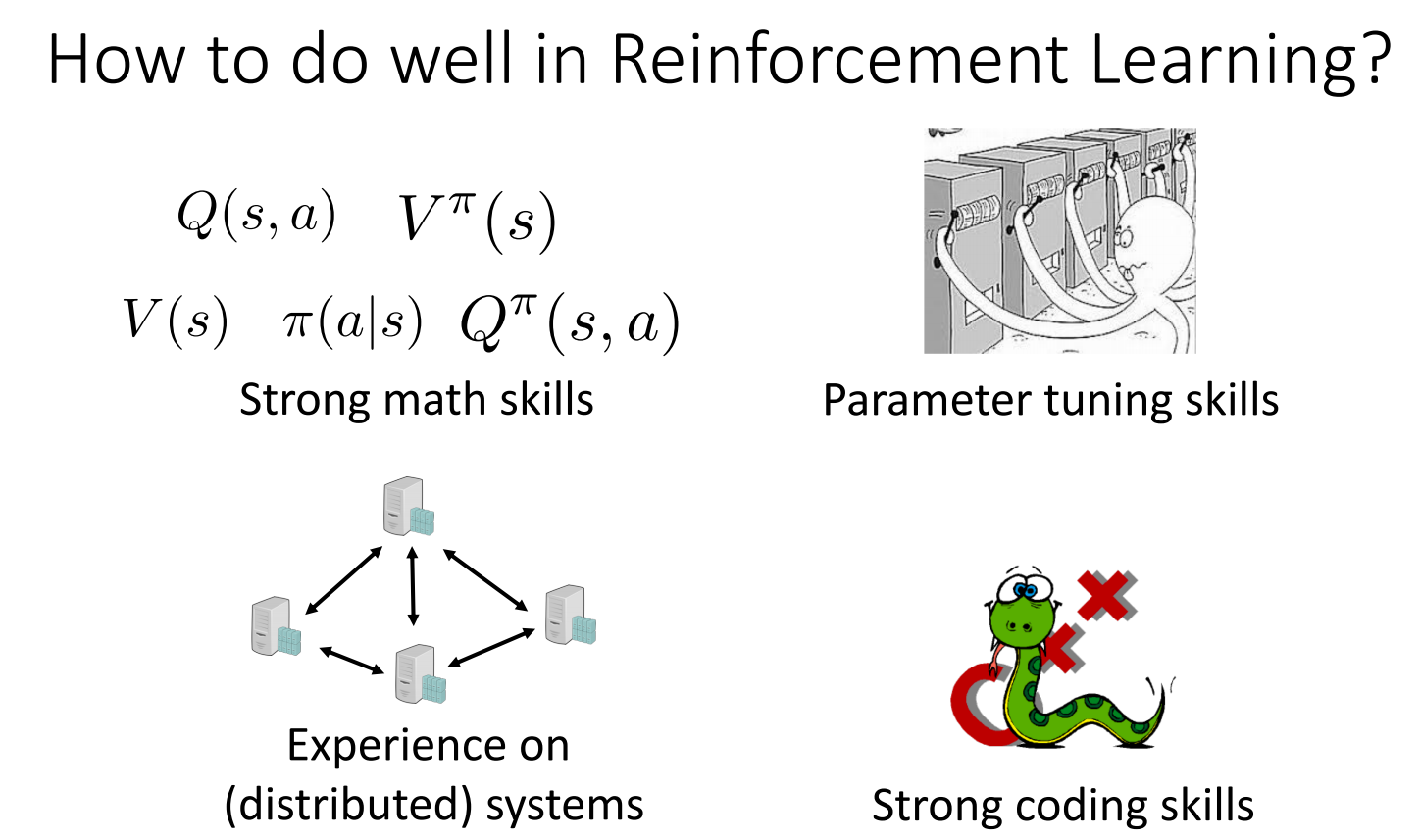
- 很好的数学基础;2. 不错的调参能力;3. 分布式系统的经验;4. 很强的编程能力。 Source: presentation2018h1.pdf #66th page
彼时我不过刚刚入门强化学习领域,对前三点自然是深表赞同,唯独对第四点持保留意见。右下角的第四幅图里,画的是C++和Python。Python程序员们有一个共识是,那就是,如果一段Python代码成为了性能瓶颈,那么就用C/C++来改写吧!然而这会导致所谓的2 language problem,其最核心的问题就是代码的可复用性与可扩展性。那时候我刚接触Julia不久,而其最大的卖点之一便是要解决这个问题,于是决定就用它来试试。使用一门比较新的编程语言来做强化学习遇到的第一个问题便是,缺少类似OpenAI Gym一样的实验环境,但是使用PyCall.jl会有明显的性能损失,于是动手用CxxWrap.jl 尝试封装了一个 ViZDoom.jl的库,碰巧这个时候,Johanni Brea写了一个经典强化学习算法的库,然后问我有没有兴趣一起来丰富这个库,经历了反复好几个版本的迭代,最终得到了现在这一相对稳定的版本,感谢 Johanni 的信任和帮助,如果没有他的支持,我恐怕是很难坚持下来的。
接下来我将简要介绍 ReinforcementLearning.jl 的一些核心特性,同时将其与一些主流强化学习库的设计做对比,分析Julia语言本身的特性对整个库的设计与实现细节的影响,最后对未来这个库可能的几个发展方向做了进一步探讨。
核心特性
快速实验
如果你还没有阅读 Get Started 部分的内容的话,强烈建议你先阅读这个部分的内容,为了方便新手快速复现一些经典算法,这里我们提供了一些内置的实验来帮助大家熟悉这个库,例如,你只需要在Julia REPL中执行以下3行代码即可快速运行基于A2C[2]
的CartPole实验:
] add ReinforcementLearning
using ReinforcementLearning
run(E`JuliaRL_A2C_CartPole`)
此外,借助Julia中提供的Artifact功能,我们将一些预训练好的模型打包上传至了云端,用户可以很方便地下载和加载预训练好的模型,用于测试和对比分析:
ID = "JuliaRL_BasicDQN_CartPole"
e = Experiment(ID)
e.agent.policy = load_policy(ID)
Flux.testmode!(e.agent)
run(e.agent, e.env, StopAfterEpisode(1), e.hook)
可以看到,这里主要是借鉴了 Stable Baselines 以及 RL Baselines Zoo 的思想,提供了一整套完整可复现的实验,不过可惜的是,受到计算资源限制,以及Julia语言中实验环境的限制,我们并没有提供像 RL Baselines Zoo中那么多的预训练好的实验(如果读者有兴趣完整运行了某个实验,欢迎发PR贡献预训练模型)。
可复现性
每一个涉及随机采样的子模块,都接受一个 rng 关键字参数作为随机数产生器,用于控制模块内部的随机化过程,这有利于同时运行多个实验时,每个实验都使用自己独立的 rng ,避免相互之间干扰,同一个实验内部,可以共享一个 rng 。不过需要注意的时,尽管我们提供的内置实验都设置了随机种子,但是由于目前底层Flux的一些原因,导致某些实验无法完全复现,希望后面的版本会解决该问题。
可扩展性
整个库最大的亮点就在可扩展性,我们将多花些时间在这方面深入讨论下。尽管最近两年涌现了许多强化学习的库,但并没有一个一家独大的库(从另外一个角度来看,也刚好说明了大家对已有的强化学习库不满,宁可动手重写),那么,我们首先来看一下已有的库都有哪些槽点,以下内容引用自 What do you think is missing from RL libraries?:
The problem with every RL lib I’ve tried is that the designers prioritise brevity-of-use over ease-of-alteration.
Lots of RL libs loooove inheritance, but inheritance sprays state over multiple files and makes adapting things to your own use a real pain. A compositional approach sacrifices something in brevity, but adds a huge amount in flexibility.
Ray RLLIB was also supposed to be high quality implementations. But it hasn’t panned out like that for them yet. It might improve in the future. But trying to make it support tf 1, tf 2 and pytorch has made the code a mess.
可以看到,这其中最大的矛盾在于,一个理想的强化学习库,既要支持大规模运行(性能),又要容易学习读得懂(教学),还要方便修改(研究)!太难了!
From the above taxonomy we conclude that there is a natural trade-off between simplicity and complexity in a deep RL research framework. The resulting choices empower some research objectives, possibly at the detriment of others. [3]
但是,多亏了Multiple Dispatch,这一点在Julia语言中得到了很好地解决,算法的实现可以先用最简洁的方式书写,遇到瓶颈之后再逐步优化,关键的地方可以有多个实现。接下来我们将自顶向下逐步介绍ReinforcementLearning.jl的可扩展性:
Anti-framework
首先我们来看下 ReinforcementLearning.jl 的代码组织结构:
+-------------------------------------------------------------------------------------------+
| |
| ReinforcementLearning.jl |
| |
| +------------------------------+ |
| | ReinforcementLearningBase.jl | |
| +--------|---------------------+ |
| | |
| | +--------------------------------------+ |
| | | ReinforcementLearningEnvironments.jl | |
| | | | |
| | | (Conditionally depends on) | |
| | | | |
| | | ArcadeLearningEnvironment.jl | |
| +-------->+ OpenSpiel.jl | |
| | | POMDPs.jl | |
| | | PyCall.jl | |
| | | ViZDoom.jl | |
| | | GridWorld.jl(WIP) | |
| | +--------------------------------------+ |
| | |
| | +------------------------------+ |
| +-------->+ ReinforcementLearningCore.jl | |
| +--------|---------------------+ |
| | |
| | +-----------------------------+ |
| |--------->+ ReinforcementLearningZoo.jl | |
| | +-----------------------------+ |
| | |
| | +----------------------------------------+ |
| +--------->+ ReinforcementLearningAnIntroduction.jl | |
| +----------------------------------------+ |
+-------------------------------------------------------------------------------------------+
ReinforcementLearning.jl 本身并不是一套用于强化学习的计算框架,它只是将许多强化学习中常用的一些模块有机地组织在了一起。之所以将其拆分成了多个子库,主要是为了敏捷开发,各个子库遵循Semantic Version发布版本号,同时可以做到依赖分离,避免造成开发某些小的功能算法的时候,依赖某些庞大的(或者是只在某些平台上才能运行的)库。各个库的基本介绍如下:
- ReinforcementLearningBase.jl 提供接口定义和某些常用算法的最小实现,其基本要求是,尽量简化其依赖,只保留基于
AbstractPolicy和AbstractEnv相关的定义、实现、与扩展。 - ReinforcementLearningCore.jl 主要以
Agent为单位展开,提供AbstractEnv与AbstractPolicy交互逻辑的基本实现,所有可复用的模块都放在这里,如AbstractExplorer(采样器),AbstractTrajectory(经验回放) 以及AbstractApproximator(近似求解器)等。 - ReinforcementLearningZoo.jl 主要基于ReinforcementLearningCore.jl 来实现各个主流深度强化学习算法,此外针对各个算法提供必要的可供复现的实验。
- ReinforcementLearningEnvironments.jl 一定程度上充当了 OpenAI Gym 的作用,用于为各种不同的强化学习实验环境提供统一的接口。
- ReinforcementLearningAnIntroduction.jl 基于 ReinforcementLearningCore.jl 实现了 Reinforcement Learning: An Introduction(2nd) 一书中涉及到的经典强化学习的算法,同时复现了书中涵盖到的例子。
可以看到,整个库中,最基本的两个抽象单位是 AbstractPolicy 和 AbstractEnv 。其基本定义如下:
(p::AbstractPolicy)(env::AbstractEnv) # return action,任意一个AbstractPolicy实例都能接受一个AbstractEnv实例作为输入,瞟一眼之后,返回action。(env::AbstractEnv)(action)接收action之后,其内部状态发生转移。
有了这两个概念之后,我们便可以模拟强化学习的过程了:
using ReinforcementLearning
p = RandomPolicy()
env = CartPoleEnv()
while !get_terminal(env)
env |> p |> env
end
这里,为了将实现的细节剥离出来,我们定义了一个 run (其实是扩展了 Base.run )函数:
function Base.run(p, env)
while !get_terminal(env)
env |> p |> env
end
end
此时, policy 与 env 仅仅互动了一个 epoch,而实际的实验中,通常需要指定学习的 终止条件 :
function Base.run(p, env, stop_condition)
is_stop = false
while !is_stop
while !get_terminal(env)
env |> p |> env
if stop_condition(p, env)
is_stop = true
break
end
end
end
end
当然,除了终止条件之外,还有很重要的一环,即 回调函数 。通常,我们在实验过程中需要记录一些重要信息,比如,收集上一个epoch 运行了多久,统计当前平均每个epoch收益是多少等等,由于这类运行时逻辑根据使用者的需求不同有很大的差异,一般无法泛化继承到一个个子模块内部,所以,大多数的机器学习库中都会将回调函数的接口暴露出来(比如Flux里的train!函数)。在 FastAI [4] 的API设计中,我们同样看到了相关的设计:
There is a rich history of using callbacks to allow for customisation of numeric software, and today nearly all modern deep learning libraries provide this functionality. However, fastai’s callback system is the first that we are aware of that supports the design principles necessary for complete two-way callbacks:
老实说,当初设计的时候其实并不知道FastAI的这套所谓的 two-way callbacks 设计,具体可以看相关的issue。
• A callback should be available at every single point that code can be run during training, so that a user can customise every single detail of the training method ;
• Every callback should be able to access every piece of information available at that stage in the training loop, including hyper-parameters, losses, gradients, input and target data, and so forth ;
这里我们也采用了类似的做法,稍稍不同的是,我们的设计中充分利用了Julia语言提供的Multiple Dispatch 功能。这里作为对比,我们来看一下FastAI中的实现逻辑:
try:
self._split(b); self.cb('begin_batch')
self.pred=self.model(*self.x); self.cb('after_pred')
iflen(self.y)==0:return
self.loss=self.loss_func(self.pred,*self.y); self.cb('after_loss')
ifnotself.training:return
self.loss.backward(); self.cb('after_back')
self.opt.step(); self.cb('after_step')
self.opt.zero_grad()
exceptCancelBatchException: self.cb('after_cancel')
finally: self.cb('after_batch')
类似地,我们结合强化学习的实际场景,定义了多个运行时的Traits:
PRE_EXPERIMENT_STAGEPRE_EPISODE_STAGEPRE_ACT_STAGEPOST_EXPERIMENT_STAGEPOST_EPISODE_STAGEPOST_ACT_STAGE
用户自定义的回调函数如果继承自 AbstractHook ,那么默认情况下在各个阶段什么都不会做:
(h::AbstractHook)(::AbstractStage, args...) = nothing
用户只需要根据实际使用需要,扩展具体某些场景下的实现即可,我们内置了许多常用的回调函数,多个回调函数又可以通过 ComposedHook 组装成一个单一的回调函数,而这其中最有意思的一个是 DoEveryNStep(f) ,即每隔 N 步就调用一次 f(t, policy, env) ,有了这个功能之后,我们可以很方便地实现某些需要周期性执行的功能,比如,定期写log记录当前变量的值,定期保存 policy 或者 env 的状态,统计当前系统的性能等等,其中我最喜欢的一个功能便是通过这个接口周期性地执行evaluation,有点像俄罗斯套娃。
除此之外,根据 policy 和 env 的不同,用户可以自己扩展出不同的 run 函数,自行决定回调函数的执行时机,甚至扩展更多的stage,例如,针对Multi-agent,Simultaneous环境的场景,可能就需要有不同的回调函数。
至此,我们就对ReinforcementLearning.jl这个库的大致运行逻辑有所了解啦!鼓励大家查看run.jl中的实现,了解和学习如何针对自己的实际使用需要,扩展出灵活的运行时逻辑。
可拔插的优化模块
前面我们用到了一个很简单的 RandomPolicy() 作为示例,介绍了 AbstractPolicy 的基本接口, (p::AbstractPolicy)(env::AbstractEnv) 。但是,大多数实际使用中的Policy要比这个复杂,我们知道,强化学习最核心的任务便是通过与环境的交互,逐渐优化策略,从而使得长期收益最大化。因此我们给 Policy 增加了一个接口:
update!(p::AbstractPolicy, experience)
这个接口相当通用,这里 experience 根据具体的 Policy 不同,可以有很多种形态,既可以是完整的历史信息,也可以是抽样信息,又或者是单步的信息等等。通常,在Julia中,我们只需要定义出最通用的一种形式即可,然后根据实际场景需要,完成相应的适配器。具体什么意思呢?这里以 QBasedPolicy 展开讲解下。
所谓 QBasedPolicy ,包含两个部分:
struct QBasedPolicy
learner
explorer
end
其中, learner 部分负责计算某个状态ss对应的Q值,而 explorer 部分则根据前面得到的Q值获取 action 。在深度强化学习领域,通常采用经验回放来训练 learner ,因此最通用的一个 update! 实现便是:
function RLBase.update!(leaner, batch::NamedTuple{(:state, :action, :reward, :terminal)})
update!(learner, batch)
end
然后,针对一些其它的 experience 做适配,比如 CircularCompactSARTSATrajectory (完整的经验):
function RLBase.update!(learner, t::CircularCompactSARTSATrajectory)
batch = extract_experience(t, p)
update!(learner, batch)
end
这样,我们便可以将算法的具体实现专注在一个最小的范围内。
在深度强化学习领域里呢,通常会使用一些深度学习的模块来实现对Q值或者VV值的近似求解。这里我们对其提供了一层统一的抽象,叫做 AbstractApproximator ,通过 update!(::AbstractApproximator, gradient) 来对其优化,这里 gradient 可以有多个来源。这样封装的好处是可以将底层的优化模块独立出来,一定程度上可以避免对某一具体DNN库的依赖。其思想也主要是来源自 RLLib [5],这样分布式的管理也更方便(尽管现在还没有)。
最早我们有对Knet.jl做适配,但是后来出于代码可维护性的考虑在某个版本中去掉了,最近正在考虑增加Torch.jl的支持。
顺便多说点,在代码库中,有一类特殊的Policy —— Agent, Agent 是个相对特殊的Policy(尽管由于历史遗留原因,其继承自 AbstractAgent ),它将其它的 Policy 与 Trajectory (即通常所说的 Experience Replay Buffer )包裹在一起,用来专门负责管理与环境交互的部分,比如什么时候往 Trajectory 中写入数据,写入什么样的数据,合适更新内部的 Policy ,区分什么时候是训练模式,什么时候是测试模式等。
Code as Config
目前大多数强化学习库的一个主流观点是,为了保证可复现性,每个实验都会有一份配置文件,比如 dopamine [3] 采用了 gin-config,还有的使用了 dict 或者 json 作为配置文件。而在我们的这个库里,采用config文件的意义不是很大,一方面必要的可配置项可以通过keyword argument暴露在Experiment的构造函数里,另外一方面,整个Experiment本身就是一个配置文件,既可以在完成构造之后手动修改,又可以在训练/测试时通过回调函数实时修改。这里我们可以简单看一下最开始提到的那个实验的结构:
ReinforcementLearningCore.Experiment
├─ agent => ReinforcementLearningCore.Agent
│ ├─ policy => ReinforcementLearningCore.QBasedPolicy
│ │ ├─ learner => ReinforcementLearningZoo.A2CLearner
│ │ │ ├─ approximator => ReinforcementLearningCore.ActorCritic
│ │ │ │ ├─ actor => Flux.Chain
│ │ │ │ │ └─ layers
│ │ │ │ │ ├─ 1
│ │ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ │ ├─ W => 256×4 Array{Float32,2}
│ │ │ │ │ │ ├─ b => 256-element Array{Float32,1}
│ │ │ │ │ │ └─ σ => typeof(NNlib.relu)
│ │ │ │ │ └─ 2
│ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ ├─ W => 2×256 Array{Float32,2}
│ │ │ │ │ ├─ b => 2-element Array{Float32,1}
│ │ │ │ │ └─ σ => typeof(identity)
│ │ │ │ ├─ critic => Flux.Chain
│ │ │ │ │ └─ layers
│ │ │ │ │ ├─ 1
│ │ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ │ ├─ W => 256×4 Array{Float32,2}
│ │ │ │ │ │ ├─ b => 256-element Array{Float32,1}
│ │ │ │ │ │ └─ σ => typeof(NNlib.relu)
│ │ │ │ │ └─ 2
│ │ │ │ │ └─ Flux.Dense
│ │ │ │ │ ├─ W => 1×256 Array{Float32,2}
│ │ │ │ │ ├─ b => 1-element Array{Float32,1}
│ │ │ │ │ └─ σ => typeof(identity)
│ │ │ │ └─ optimizer => Flux.Optimise.ADAM
│ │ │ │ ├─ eta => 0.001
│ │ │ │ ├─ beta
│ │ │ │ │ ├─ 1
│ │ │ │ │ │ └─ 0.9
│ │ │ │ │ └─ 2
│ │ │ │ │ └─ 0.999
│ │ │ │ └─ state => IdDict
│ │ │ │ ├─ ht => 32-element Array{Any,1}
│ │ │ │ ├─ count => 0
│ │ │ │ └─ ndel => 0
│ │ │ ├─ γ => 0.99
│ │ │ ├─ max_grad_norm => Nothing
│ │ │ ├─ norm => 0.0
│ │ │ ├─ actor_loss_weight => 1.0
│ │ │ ├─ critic_loss_weight => 0.5
│ │ │ ├─ entropy_loss_weight => 0.001
│ │ │ ├─ actor_loss => 0.0
│ │ │ ├─ critic_loss => 0.0
│ │ │ ├─ entropy_loss => 0.0
│ │ │ └─ loss => 0.0
│ │ └─ explorer => ReinforcementLearningCore.BatchExplorer
│ │ └─ explorer => ReinforcementLearningCore.GumbelSoftmaxExplorer
│ │ └─ rng => Random._GLOBAL_RNG
│ ├─ trajectory => ReinforcementLearningCore.CombinedTrajectory
│ │ ├─ reward => 16×0 ReinforcementLearningCore.CircularArrayBuffer{Float32,2}
│ │ ├─ terminal => 16×0 ReinforcementLearningCore.CircularArrayBuffer{Bool,2}
│ │ ├─ state => 4×16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,3}, :, :, 1:0) with eltype Float32
│ │ ├─ next_state => 4×16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,3}, :, :, 2:1) with eltype Float32
│ │ ├─ full_state => 4×16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Float32,3}, :, :, 1:0) with eltype Float32
│ │ ├─ action => 16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,2}, :, 1:0) with eltype Int64
│ │ ├─ next_action => 16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,2}, :, 2:1) with eltype Int64
│ │ └─ full_action => 16×0 view(::ReinforcementLearningCore.CircularArrayBuffer{Int64,2}, :, 1:0) with eltype Int64
│ ├─ role => DEFAULT_PLAYER
│ └─ is_training => true
├─ env => ReinforcementLearningBase.MultiThreadEnv: ReinforcementLearningBase.SingleAgent(),ReinforcementLearningBase.Sequential(),ReinforcementLearningBase.PerfectInformation(),ReinforcementLearningBase.Deterministic(),ReinforcementLearningBase.StepReward(),ReinforcementLearningBase.GeneralSum(),ReinforcementLearningBase.MinimalActionSet()
├─ stop_condition => ReinforcementLearningCore.StopAfterStep
│ ├─ step => 100000
│ ├─ cur => 1
│ └─ progress => ProgressMeter.Progress
├─ hook => ReinforcementLearningCore.TotalBatchRewardPerEpisode
│ ├─ rewards => 16-element Array{Array{Float64,1},1}
│ └─ reward => 16-element Array{Float64,1}
└─ description => "# A2C with CartPole"
那这样有什么好处呢?一方面是直观,我们可以很清楚地看到整个实验的结构及具体的配置项,另外一方面是,我们可以利用回调函数实现许多运行时需要修改的逻辑,从而避免模块之间的相互依赖。比如,在一些算法中,我们希望学习率能根据当前训练进度做调整,通常的做法是在内部封装一个计数器,但是假如我希望根据当前agent训练的效果做动态调整呢?很不幸,那意味着你要拿到完整的运行时信息,这就与我们的模块分离的设计相违背了。但是在我们的设计里,学习速率只是很普通的一个参数,我们可以通过回调函数修改它即可。
可复用的Trajectory
在 rlpyt [6] 中,作者着重强调了一类数据结构, namedarraytuple 。在我们的库中,也有类似的实现,即 AbstractTrajectory 。不过,得益于Julia生态中丰富的 Array 类型,我们可以易用性和高性能之间找到一个很好的平衡点:
简单来说呢, AbstractTrajectory 是一个类似 NamedTuple 的结构,只不过这里为了避免 TypePiracy 的问题,我们构造了一类自己的结构,其中最基本的一种就是 Trajectory :
t = Trajectory(reward=[], terminal=[])
t[:reward] # []
haskey(t, :reward) # true
keys(t) # (:reward, :terminal)
上面这个 Trajectory 使用最基本的 Vector 作为容器,提供了两个 trace 用来记录 reward 和 terminal ,这里容器可以替换成其它各种类型的 Array ,比如 ElasticArray。在我们的库里,广泛使用的一类容器是 CircularArrayBuffer ,主要用于经验回放。其优势在与节省了额外的内存开销,我们可以借助 view 方便快速地读取其中的某些片段。此外还有一类 SharedTrajectory 主要用于多个子 trace 共享同一个容器的情况。最后还有一类容器是 CombinedTrajectory ,用于将多个 Trajectory 合并在一起,从而方便用户在定义新的 Trajectory 地时候,复用库中已有的 Trajectory 。比如,在支持 legal_actions_mask 的时候,又或者是使用 Prioritized Experience Replay Buffer 的时候。
Case Study PPO
接下来,我们以 PPO [7]
算法为例,深入讲解其实现细节。之所以选择PPO算法是因为该算法的实现有许多有意思的细节,如果你读过Implementation Matters in Deep RL: A Case Study on PPO and TRPO[8]
就会明白,这其中的许多实现细节会对该算法的最终效果产生较大的影响,接下来我们就来看看如何用 ReinforcementLearning.jl 这个库,用Julia来实现PPO算法中的这些细节。
首先我们需要知道,PPO算法既可以用于连续动作空间的任务,也可以用作离散动作空间的任务,在ReinforcementLearning.jl中,我们实现的是离散动作空间的PPO(欢迎大家发PR贡献连续动作空间的版本噢~),因此,我们可以定义一个 PPOLearner ,它的作用就是估计Q值,和前面一样,把它作为 QBasedPolicy 中的 learner ,和 explorer 放在一起,即可针对某个连续动作空间的环境返回相应的动作了。这里 explorer 的选择一般直接用 WeightedExplorer (需要注意,内置的这个版本没有做softmax),或者是 GumbelSoftmaxExplorer 。于是,目前为止我们的代码结构如下:
struct PPOLearner
# TODO
end
p = QBasedPolicy(
learner = PPOLearner(),
explorer = GumbelSoftmaxExplorer(),
)
PPO算法本身属于Policy Gradient 1 算法,其核心的优化器仍采用的是Actor-Critic结构,这里先看一下 PPO-Clip 这一算法的目标函数:
其中:
仔细分析可以看到,除了需要在实验过程中记录 s_t,a_t ,计算 \hat{A} 时需要记录 r_t, t_t 之外,为了避免重复计算 \pi_\theta(a_t|s_t) ,我们可以将其顺便也记录下来。因此,需要定制一个 PPO 专用的 Trajectory :
function PPOTrajectory(; capacity, action_log_prob_size = (), action_log_prob_type = Float32, kw...,)
CombinedTrajectory(
SharedTrajectory(
CircularArrayBuffer{action_log_prob_type}(
action_log_prob_size...,
capacity + 1,
),
:action_log_prob,
),
CircularCompactSARTSATrajectory(; capacity = capacity, kw...),
)
end
由于现在,我们要求 QBasedPolicy{<:PPOLearner} 返回 (action, log_prob) 这样的pair,打破了之前关于 (p::AbstractPolicy)(env::AbstractEnv) 的假设,不过没关系,Julia中对返回值并没有做限制,我们只需要扩展用到该返回值的地方,将其中的action取出来即可。
最理想的做法是,构造一个新的结构体,比如 ActionWithProb ,然后将所有用到它的函数都扩展下。不过,这里我偷懒只是简单用了个 tuple 。
比如,在 PreActStage 将 \pi_\theta(a_t|s_t) 塞入 PPOTrajectory :
function (agent::Agent{<:AbstractPolicy,<:PPOTrajectory})(::Training{PreActStage}, env)
action, action_log_prob = agent.policy(env)
state = get_state(env)
push!(
agent.trajectory;
state = state,
action = action,
action_log_prob = action_log_prob,
)
# update policy when necessary
end
剩下的就是根据PPO的算法,完善优化 PPOLearner 部分啦:
function RLBase.update!(learner::PPOLearner, t::PPOTrajectory)
#... see more details at https://github.com/JuliaReinforcementLearning/ReinforcementLearningZoo.jl/blob/cf9bf197bc2b0493c329112cbdf41abe9523403e/src/algorithms/policy_gradient/ppo.jl#L102-L187
end
接下来我们看看 Implementation Matters in Deep RL: A Case Study on PPO and TRPO 中提到的一些trick如何实现:
- Value function clipping 这块的具体实现可以查看ReinforcementLearningZoo.jl 中
PPOLearner的源码,并不复杂。多说一句,某些时候希望动态地调整clip_ratio,可以通过回调函数来实现。 - Reward scaling/Reward clipping 可以通过ReinforcementLearningBase.jl 中的
RewardOverriddenEnv很方便地定制。 - Orthogonal initialization and layer scaling 目前 Orthognal Initialization 在Flux中并没有提供,我们在 ReinforcementLearningCore.jl中提供了相应的函数。
- Adam learning rate annealing 类似learning rate,也可以通过回调函数实现。
- Observation Normalization/Clipping 可以通过往
StateOverridenEnv中加入相应的处理函数实现。 - Global Gradient Clipping ReinforcementLearningCore.jl 中提供了
global_norm的实现。 - Hyperbolic tan activation 直接在
NeuralNetworkApproximator层内部实现即可。
整体的性能对比
当然,大家选择使用某个库的时候,除了灵活性之外,最重要的一方面还是运行时效率,这里列出一些内置实验的运行速度,尽管这里用到的配置尽量和rlpyt 或者是 dopamine中的默认配置保持一致,但运行效率上并不好直接做公平的比较,所以仅给出了内置实验的运行速度,以下数据仅用于对比不同算法的运行效率:
The following data are collected from experiments on Intel(R) Xeon(R) W-2123 CPU @ 3.60GHz with a GPU card of RTX 2080ti .
| Experiment | FPS | Notes |
|---|---|---|
EDopamine_DQN_Atari(pong)`` |
~210 | Use the same config of dqn.gin in google/dopamine |
EDopamine_Rainbow_Atari(pong)`` |
~171 | Use the same config of rainbow.gin in google/dopamine |
EDopamine_IQN_Atari(pong)`` |
~162 | Use the same config of implicit_quantile.gin in google/dopamine |
Erlpyt_A2C_Atari(pong)`` |
~768 | Use the same default parameters of A2C in rlpyt with 4 threads |
Erlpyt_PPO_Atari(pong)`` |
~711 | Use the same default parameters of PPO in rlpyt with 4 threads |
思考
目前来看,ReinforcementLearning.jl 所提供的大致是以下几个库的集合:
- ShangtongZhang/reinforcement-learning-an-introduction
- google/dopamine
- Spinning Up TD3和TRPO没有实现(至少我没看到实现起来有什么太难的地方,就交给热心开源贡献的小伙伴们啦~)
有一些想做但还没有时间做的事情:
- 一些Multi-Agent相关的算法正在实现,但可能会花比较长的时间
- Model Based的一些算法还没涵盖
- 已有算法的recurrent版本改进
- 集成AlphaZero
- 写一个相对通用高效的MCTS实现
还有一些想做但没有资源做的事情:
- 多GPU、跨机器并行的大规模算法实现(类似seed-rl)
剩下还有一些希望有社区里其它人来做的事情:
- 写更多强化学习环境相关的wrapper(许多强化学习相关的环境都是C/C++写的,其实用CxxWrap.jl或者Clang.jl封装一下就可以用了)
- 写一些控制相关的环境(continuous control相关的环境太少了…)
最后,用一首我比较喜欢的诗作为结尾:
Masons, when they start upon a building,
Are careful to test out the scaffolding;
Make sure that planks won’t slip at busy points,
Secure all ladders, tighten bolted joints.
And yet all this comes down when the job’s done
Showing off walls of sure and solid stone.
So if, my dear, there sometimes seem to be
Old bridges breaking between you and me
Never fear. We may let the scaffolds fall
Confident that we have built our wall.
(“Scaffolding” by Seamus Heaney, 1939–2013)
希望这个库能给你带来不一样的思考,让你有信心用Julia设计出更优秀的算法!
- A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D., Graepel, T. and others, 2018. Science, Vol 362(6419), pp. 1140–1144. American Association for the Advancement of Science. - Asynchronous methods for deep reinforcement learning
Mnih, V., Badia, A.P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D. and Kavukcuoglu, K., 2016. International conference on machine learning, pp. 1928–1937. - Dopamine: A research framework for deep reinforcement learning
Castro, P.S., Moitra, S., Gelada, C., Kumar, S. and Bellemare, M.G., 2018. arXiv preprint arXiv:1812.06110. - Fastai: A layered API for deep learning
Howard, J. and Gugger, S., 2020. Information, Vol 11(2), pp. 108. Multidisciplinary Digital Publishing Institute. - {RL}lib: Abstractions for Distributed Reinforcement Learning [HTML]
Liang, E., Liaw, R., Nishihara, R., Moritz, P., Fox, R., Goldberg, K., Gonzalez, J., Jordan, M. and Stoica, I., 2018. , Vol 80, pp. 3053–3062. PMLR. - rlpyt: A research code base for deep reinforcement learning in pytorch
Stooke, A. and Abbeel, P., 2019. arXiv preprint arXiv:1909.01500. - Proximal policy optimization algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. and Klimov, O., 2017. arXiv preprint arXiv:1707.06347. - Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos, F., Rudolph, L. and Madry, A., 2019. International Conference on Learning Representations.