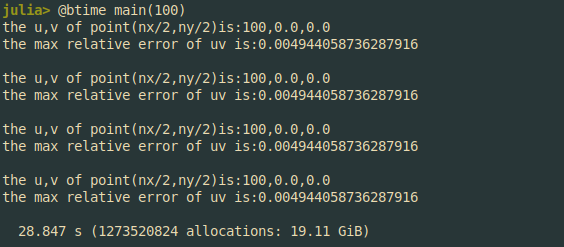
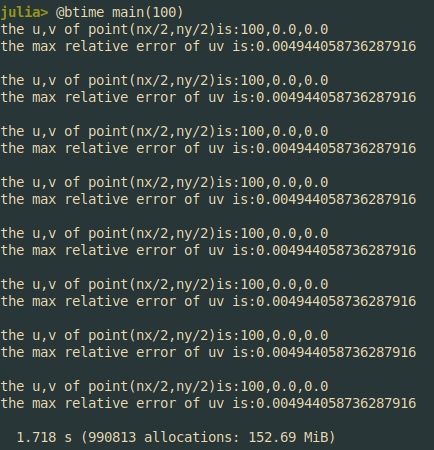
自己初学julia语言,终于把毕设的雏形做出来了,但是运行计算速度实在是很慢,又无从下手,等几个大佬来优化一下QwQ
# code
global cx = [0,1,0,-1,0,1,-1,-1,1] #水平方向速度分量
global cy = [0,0,1,0,-1,1,1,-1,-1] #锤子方向速度分量
global w = [4.0 / 9.0,1.0 / 9.0,1.0 / 9.0,1.0 / 9.0,1.0 / 9.0,1.0 / 36.0,1.0 / 36.0,1.0 / 36.0,1.0 / 36.0]
mstep=1000
nx=256
ny=256
Q=9
rho0=1.0
U=0.1
dx=1.0
dy=1.0
Lx=dx*nx
Ly=dy*ny
dt=dx
c=dx/dt
Re=1000
niu=U*Lx/Re
tau=3.0*niu+0.5
f=zeros(Float64,nx+1,ny+1,Q)
F=zeros(Float64,nx+1,ny+1,Q)
u = ones(Float64, nx+1, ny+1) #水平速度
u0 = ones(Float64, nx+1, ny+1)
v = ones(Float64, nx+1, ny+1) #垂直速度
v0 = ones(Float64, nx+1, ny+1)
rho = ones(Float64, nx+1, ny+1) #初试密度
function ph(k,rho,u,v)
t1=cx[k]*u+cy[k]*v
t2=u*u+v*v
feq=w[k]*rho*(1.0+3.0*t1+4.5*t1*t1-1.5t2)
return feq
end
function evolution()
for i=2:nx
for j=2:nx
for k=1:Q
ip=i-cx[k]
jp=j-cy[k]
F[i,j,k]=f[ip,jp,k]+(ph(k,rho[ip,jp],u[ip,jp],v[ip,jp])-f[ip,jp,k])/tau
end
end
end
for i=2:nx
for j=2:ny
u0[i,j]=u[i,j]
v0[i,j]=v[i,j]
rho[i,j]=0
u[i,j]=0
v[i,j]=0
for k=1:Q
f[i,j,k]=F[i,j,k]
rho[i,j]+=f[i,j,k]
u[i,j]+=cx[k]*f[i,j,k]
v[i,j]+=cy[k]*f[i,j,k]
end
u[i,j]/=rho[i,j]
v[i,j]/=rho[i,j]
end
end
for j=2:ny
for k=1:Q
rho[nx+1,j]=rho[nx,j]
f[nx+1,j,k]=ph(k,rho[nx+1,j],u[nx+1,j],v[nx+1,j])+f[nx,j,k]-ph(k,rho[nx,j],u[nx,j],v[nx,j])
rho[1,j]=rho[2,j]
f[1,j,k]=ph(k,rho[1,j],u[1,j],v[1,j])+f[2,j,k]-ph(k,rho[2,j],u[2,j],v[2,j])
end
end
for i=2:nx
for k=1:Q
rho[i,1]=rho[i,2]
f[i,1,k]=ph(k,rho[i,1],u[i,1],v[i,1])+f[i,2,k]-ph(k,rho[i,2],u[i,2],v[i,2])
rho[i,ny+1]=rho[i,ny]
u[i,ny+1]=U
f[i,ny+1,k]=ph(k,rho[i,ny+1],u[i,ny+1],v[i,ny+1])+f[i,ny,k]-ph(k,rho[i,ny],u[i,ny],v[i,ny])
end
end
end
for i=1:nx+1
for j=1:ny+1
u[i,j]=0
v[i,j]=0
rho[i,j]=rho0
u[i,ny+1]=U
for k=1:Q
f[i,j,k]=ph(k,rho[i,j],u[i,j],v[i,j])
end
end
end
for kk=1:mstep
evolution()
if(kk%100==0)
println("the u,v of point(nx/2,ny/2)is",u[129,129],",",v[129,129])
end
end