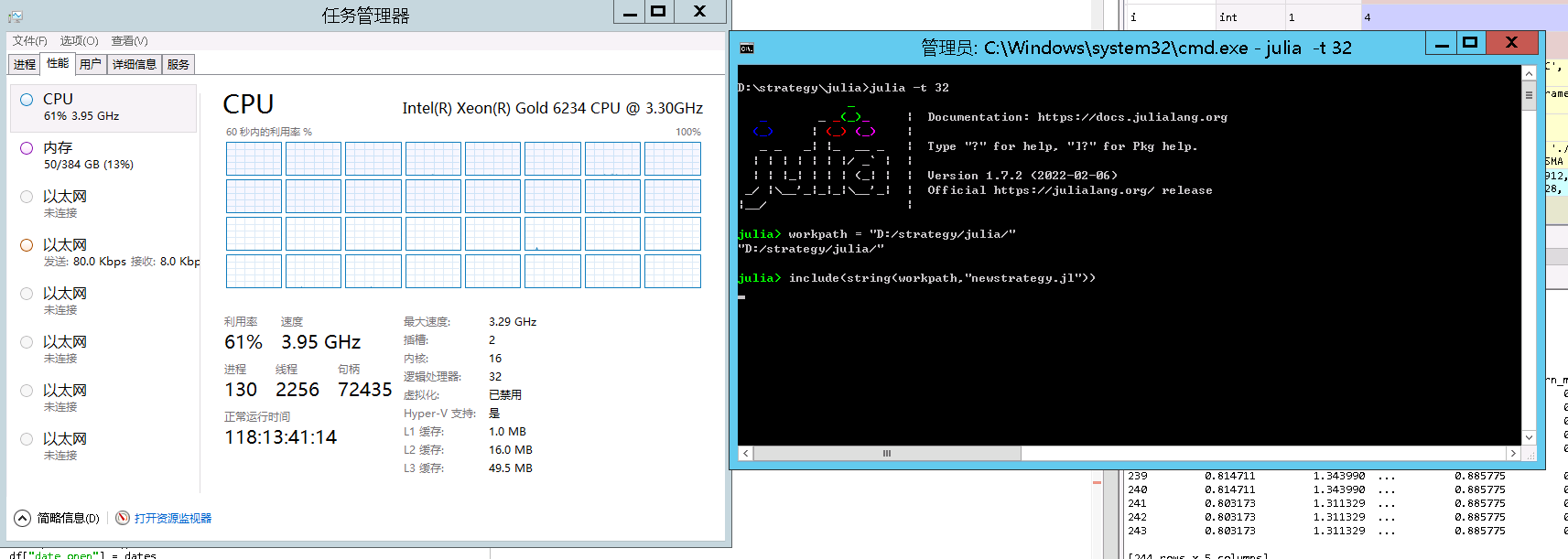
如图所示,我这个服务器的配置是2CPU,32个逻辑核心。我用
julia -t 32
来创建32个线程,但是实际跑起来的时候,只用了一个CPU的资源,如图所示,似乎全部的32线程都创建在第一个CPU上。julia是不是没法跨CPU来创建线程?
julia -t 32
来创建32个线程,但是实际跑起来的时候,只用了一个CPU的资源,如图所示,似乎全部的32线程都创建在第一个CPU上。julia是不是没法跨CPU来创建线程?
julia是不是没法跨CPU来创建线程?
是可以的,但这和具体的代码有关。julia -t 32 分配了32个可用线程给 Julia 但并不意味着你的代码会调用到这 32 个线程:它们可能只会调用主线程在工作。
function load_data2(db_id::UInt64, dates::Vector{Date})
datesint = parse.(Int, Dates.format.(dates,"yyyymmdd"))
files = string.("marketdata/tick_",datesint)
futureticks2d = Vector{Vector{FuturesTick}}()
margin_ratio2d = Vector{Dict{String,Integer}}()
symbols2d = Vector{Vector{String}}()
datetimes2d = Vector{Vector{NTuple{2,Integer}}}()
for i in eachindex(files)
futureticks = FuturesTick[]
margin_ratio = Dict{String,Integer}()
symbols = Vector{String}()
datetimes = Vector{NTuple{2,Integer}}()
push!(futureticks2d, futureticks)
push!(symbols2d, symbols)
push!(datetimes2d, datetimes)
push!(margin_ratio2d, margin_ratio)
end
Threads.@threads for i in eachindex(files)
futureticks = futureticks2d[i]
futureitems = HDataItem[]
margin_ratio = margin_ratio2d[i]
file = files[i]
datei = datesint[i]
# (file_id, type_num, ci_type_r, data_types) = hdb_open_file(db_id, file, flags)
file_id = hdb_open_file(db_id, file, flags)[1]
load_futureticks!(file_id, futureitems, futureticks)
load_codeinfo!(file_id, margin_ratio)
datetimes = parsedatetime.(futureitems)
symbols = parsesymbols(futureitems)
symbols2d[i] = symbols
datetimes2d[i] = datetimes
hdb_close_file(file_id)
println(file," has loaded")
end
return symbols2d, datetimes2d, futureticks2d, margin_ratio2d
end
我的代码是这样的,其中files是一个250元素的Vector。如果这样调用的话,应该可以把所有线程都用起来吧?
同样的代码,我在一个单CPU的机器上,是可以把所有逻辑核心都用起来的。
这个地方我说的不够准确,线程应该是确实创建了32个,但是似乎都创建在了同一个CPU上。
不是很确定,也许和 windows 操作系统本身的调度有关。
这是我在 linux (两块 E5-2678 v3 CPU)上测试的情况:
# test_threads.jl
@show Threads.nthreads()
x = rand(4096, 4096)
out = [zeros(size(x)) for _ in 1:Threads.nthreads()]
Threads.@threads for i in 1:1000*Threads.nthreads()
out[i%Threads.nthreads() + 1] .+= x .* x
end
julia --threads=auto test_threads.jl
现在各个语言对线程的调用概念中,好像都存在一个语言层面的线程和操作系统层面的线程的映射关系。我并不清楚Julia具体是怎么操作的;但你这里Julia直接就能1:1把Julia线程映射到硬件线程,应该类似于之前我在linux cluster上一个节点(比如两个16核cpu)跑多线程?
而题主遇到的问题,大概就是在windows上多核无法一一映射?
当然跨节点就不灵了,因为服务器上的每个节点其实都是一个独立的系统。
Windows的锅
