提供一点数据样本吧,比如提供100 或者1000条样本。
chr1 的位点在chr1df的好几行中,在最终的结果里面也只需要出现一次吧?
using GenomicFeatures
using DataFrames
chr1df = [
Interval("chr1", 10628, 10683, '?', "abc")
Interval("chr1", 10643, 10779, '?', "abc")
Interval("chr1", 10645, 10748, '?', "abc")
Interval("chr1", 10648, 10786, '?', "abc")
Interval("chr1", 10676, 10767, '?', "abc")
Interval("chr1", 10690, 10731, '?', "abc")
Interval("chr1", 10707, 10793, '?', "abc")
Interval("chr1", 10742, 10814, '?', "abc")
] |> IntervalCollection
chr1= [
Interval("chr1", 10631, 10631)
Interval("chr1", 10633, 10633)
Interval("chr1", 10636, 10636)
Interval("chr1", 10638, 10638)
Interval("chr1", 10641, 10641)
Interval("chr1", 10644, 10644)
Interval("chr1", 10645, 10645)
Interval("chr1", 10650, 10650)
] |> IntervalCollection
chr1df=DataFrame(chr1df)
chr1=DataFrame(chr1)
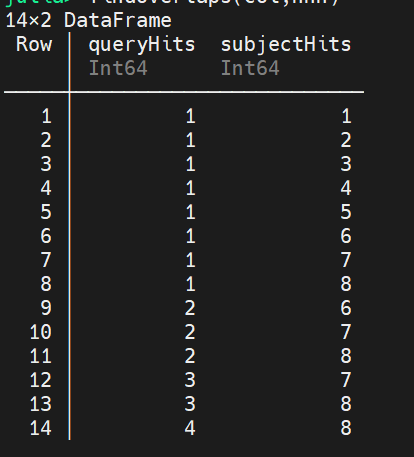
可以看出chr1的1-8行都在ch1df的第一行中,chr1的第6行 10644也在chr1df的第二行10643-10779之间。
不是,是要全出现,下面评论是测试数据
返回的 Vector{Bool},
function findoverlap2(vecx, vecy)
index_x = 1
index_y = 1
length_x = size(vecx,1)
length_y = size(vecy, 1)
ans = falses(length_x)
while index_x <= length_x && index_y <= length_y
if vecx[index_x,:first] < vecy[index_y,:first]
# 小于下界,
index_x += 1
elseif vecx[index_x,:first] >= vecy[index_y, :first] && vecx[index_x,:first] <= vecy[index_y, :last]
ans[index_x] = true
index_x += 1
else
# 大于上界
index_y += 1
end
end
return ans
end
然后这个应该就是你要的结果。
z=findoverlap2(chr1,chr1df)
chr1[z,:]