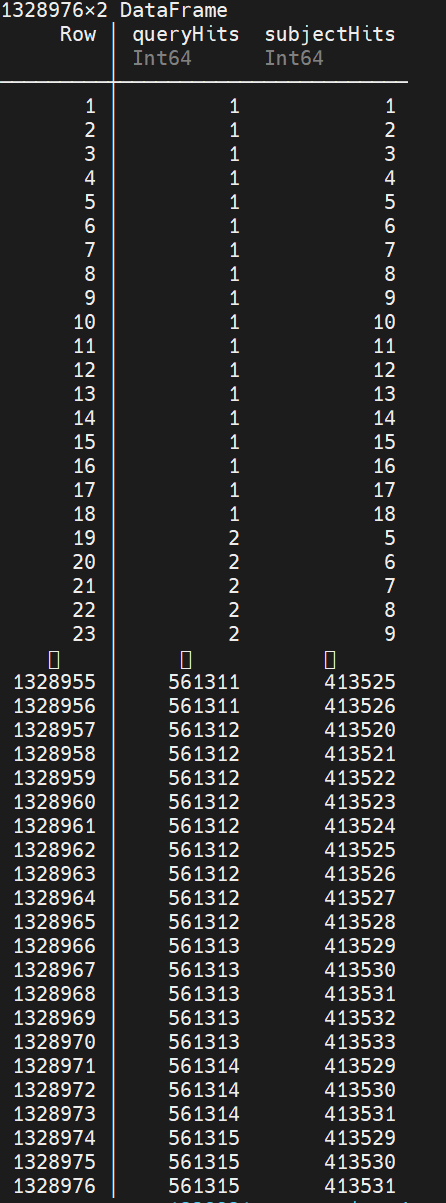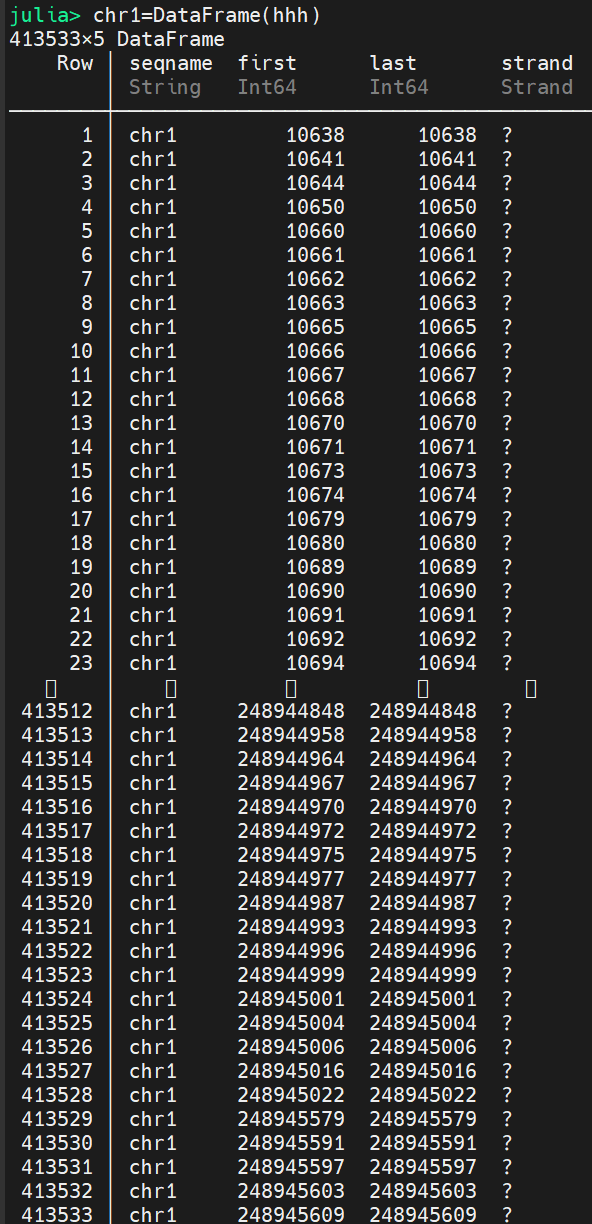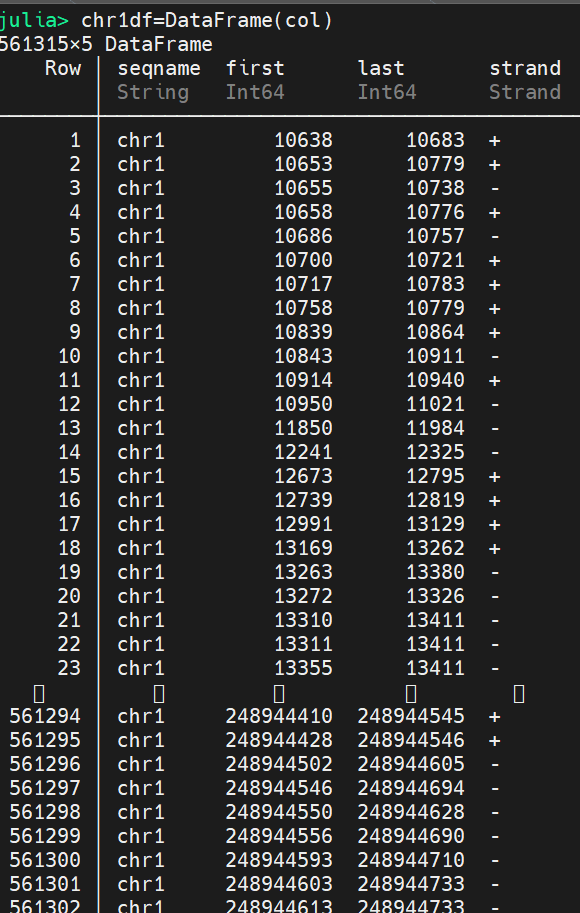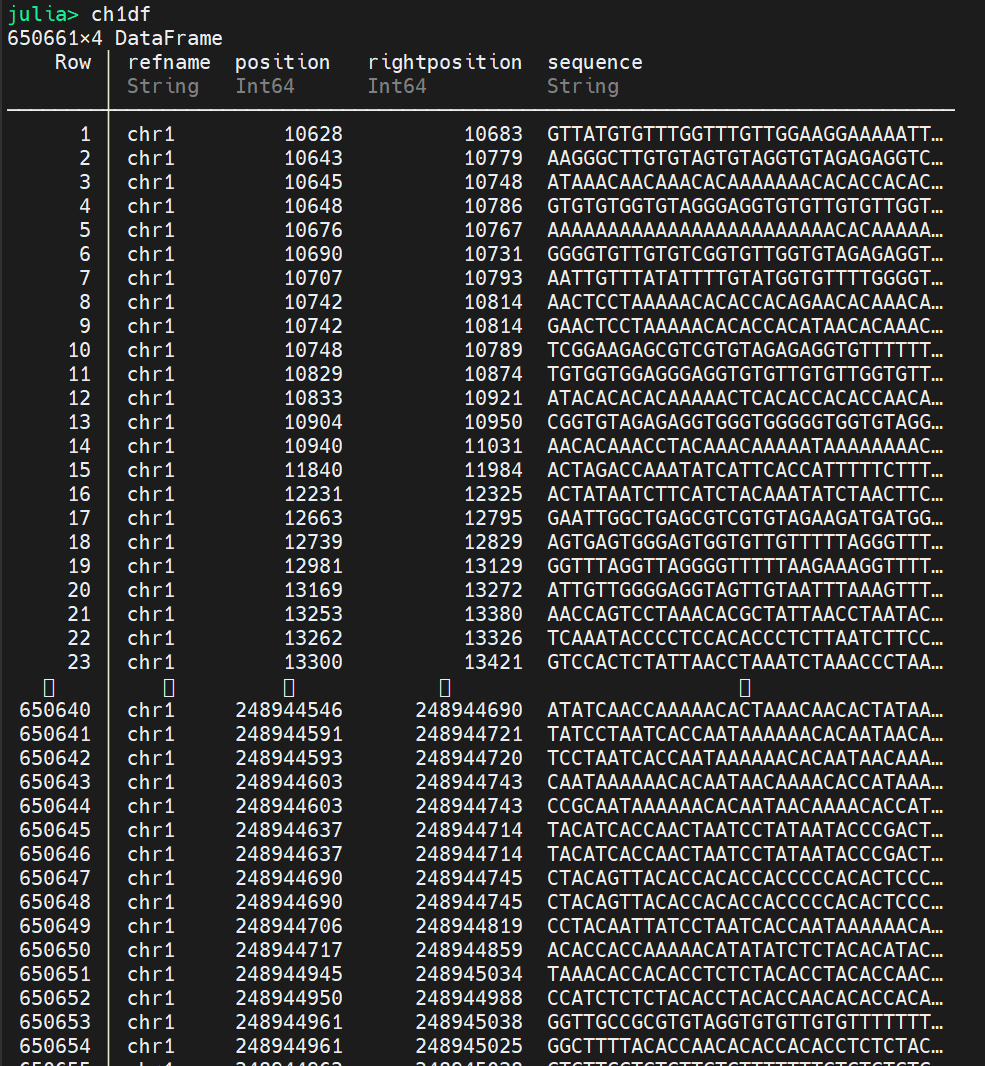
我的问题是这样的,如果第一个dataframe chr1的第三列在第二个dataframe ch1df position 和rightposition里面,就返回我的ch1df的行号
比如ch1df的10628-10683之间能与chr1匹配上,ch1df的第一行取出来。ch1df的第二行10643-10779能与chr1的第6行10644匹配上,第二行也要。大概就是这个意思,这个要怎么写才能高效完成呢?
你这个不是程序的问题啊,是算法的问题。
貌似这里的区间都是单调的吧。
我唯一能想到的就是,在针对左边某一行查找的时候,右边对j:end查找。这里的j会变的。
比如:左边chr1第6行,在右边第1行就不匹配了,但是在第2行匹配。下次chr1第7行就从右边第2行开始搜索。
然后我看到左边一个数据,右边有好几个区间都是满足的。你可以设置一个判断:前一次在区间里头,后一次不在了,就没必要往下找了,直接退出右边的循环。
这样在对右边搜索时,只是一个移动的小区间。既不是1:end,也不是j:end。
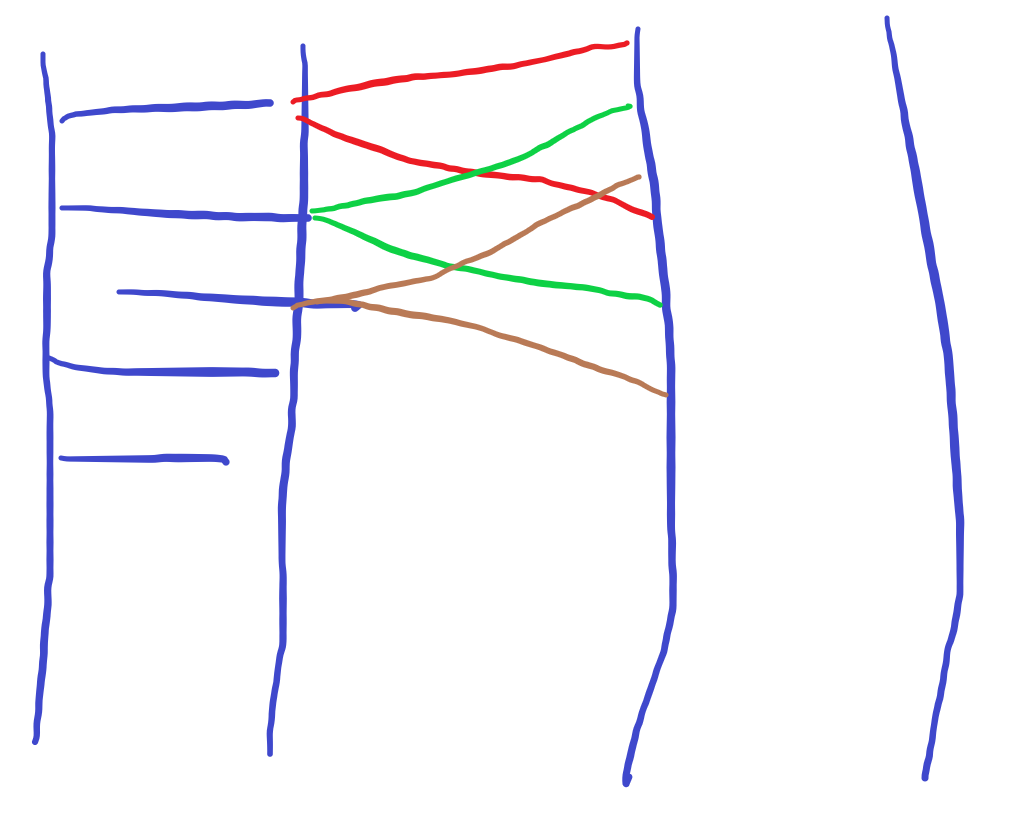
这个感觉像是位点在序列上的注释?我感觉可以参考下别人perl脚本里的写法
好的谢谢我去尝试一下
好的我去参考一下,感谢
感觉最省力复杂度也不算大的方法是用二分查找,对于一个区间[l, r],查找第一个小于l的数,如果这个数的下一个数大于r则该区间不被选中,复杂度为 O(m \log n) 。
1 个赞
chr1 的 row7 对应 ch1df 的 row1 row2 row3, 都要取出吗?
ch1df 可以 按 position 排序吗?
是的,都取出来。我其实是用julia模仿R语言中的findoverlaps那个函数,想用julia写一个。
有模仿对象就简单一些。
先理一理原函数的逻辑,准备一些测试的输入输出。
然后 julia 仿写,等测试都通过了,最后再优化性能。
好的谢谢您的指导

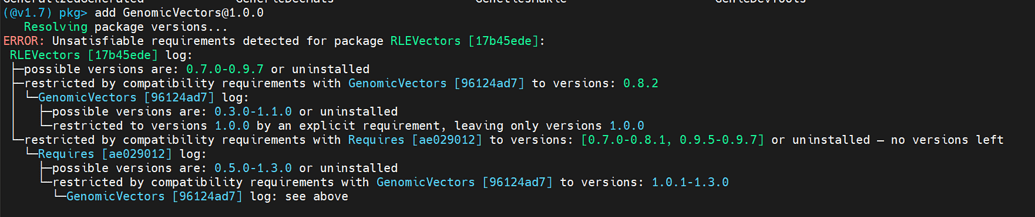
你可以安装么这个包么?
(@v1.6) pkg> add https://github.com/phaverty/GenomicVectors.jl
windows下1.6试了可以
ch1df 要排序。感觉你这个如果用 GPU 来写 kernel 会很快。
手写也应该没有几行。
仔细读了下描述跟数据,发现这样子不得行。以下作废
说一个我觉得比较简单的方法吧,用队列,先进先出。复杂度大概是 O(m+n) 吧
vecx 与 vecy 都要有序(比如都升序),返回两者共同的部分。你稍微改一下就是你需要的了。
function findoverlap(vecx::Vector{T}, vecy::Vector{T})::Vector{T} where {T}
q = Queue{T}()
ans = T[]
i = 1
for x in vecx
enqueue!(q, x)
end
while i < length(vecy)
if vecy[i] == first(q)
push!(ans, dequeue!(q))
i += 1
elseif vecy[i] > first(q)
dequeue!(q)
end
if isempty(q)
break
end
end
return ans
end
下面是一个例子
julia> x = [i for i in 1:10]
julia> y = [i for i in 5:15]
julia> z = findoverlap(x, y)
6-element Vector{Int64}:
5
6
7
8
9
10
想复杂了,实际上用双指针更简单。
function findoverlap2(vecx::Vector{T}, vecy::Vector{T}) where {T}
ans = T[]
index_x = 1
index_y = 1
length_x = length(vecx)
length_y = length(vecy)
while index_x <= length_x && index_y <= length_y
if vecx[index_x] < vecy[index_y]
index_x += 1
elseif vecx[index_x] == vecy[index_y]
push!(ans, vecx[index_x])
index_x += 1
index_y += 1
else
index_y += 1
end
end
return ans
end
我在linux服务器装不上啊,windows也装不上,你装上后会与包有冲突么?
我在干净环境试的,你要是冲突就在不同的环境里用这个包,用文件跟其他模块交互吧