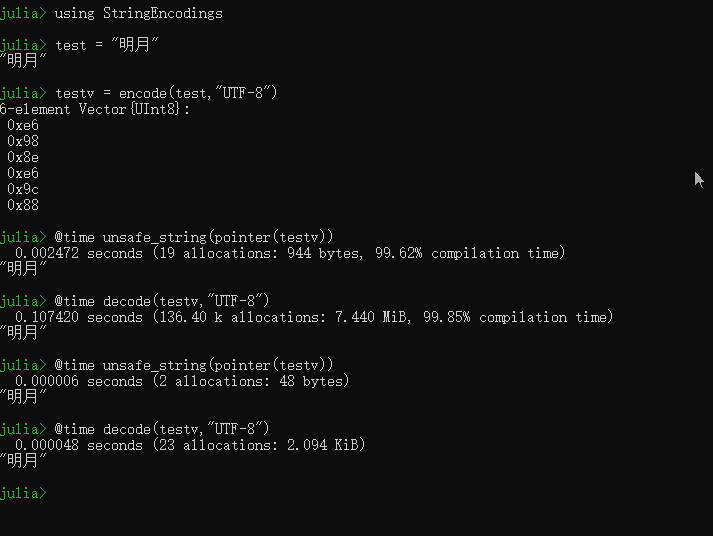
如图所示, 解析一个通过UTF-8编码的UInt8的字符串,有两种方式:
方式一是先转换成指针,再用unsafe_string来解码。
方式二是使用StringEncodings里面的decode模块。
从图片可以看出,第一次运行时,方式一的速度是方式二的50倍,第二次运行时,方式二的速度是方式一的8倍。为啥这两种方式速度差异这么大?
对于UTF-8编码的字符串而言,方式一确实已经够用了,但是如果是GBK编码,如何快速解码呢?
对于UTF-8编码的字符串而言,方式一确实已经够用了,但是如果是GBK编码,如何快速解码呢?
用 @btime 来测试,你去论坛里搜搜这一方面的帖子
Julia 字符串使用 UTF-8 编码,用 UTF-8 编解码更快。
实际上 UTF-8 字符串建议用自带函数,比如
julia> using BenchmarkTools
julia> msg = "abαβ你好";
julia> encode = @btime codeunits(msg)
14.278 ns (1 allocation: 16 bytes)
12-element Base.CodeUnits{UInt8, String}:
julia> data = @btime Vector{UInt8}(msg)
157.557 ns (1 allocation: 96 bytes)
12-element Vector{UInt8}:
调包反而更慢
using StringEncodings, BenchmarkTools
msg = "abαβ你好";
data = @btime encode(msg, "UTF-8")
# 2.061 μs (22 allocations: 1.30 KiB)
同样地,解码建议用自带函数 String,比如
encode = codeunits(msg);
# 加 copy 由于 String 解析过程会清空输入数列,参见 String 文档
msg = @btime String(copy(data))
# 147.540 ns (2 allocations: 128 bytes)
# "abαβ你好"
msg = @btime decode(data, "UTF-8")
# 1.913 μs (23 allocations: 2.23 KiB)
# "abαβ你好"
按编码规则手写一个?比如写个字典,GBK一共 2^16=65536 个字符。

是这样的,我这边要处理的UInt8的字符串,往往是图中这种固定长度的,剩余部分会以0结尾。我用unsafe_string的方式处理,它会自动把末尾的零给抹掉。得到
"明月"
而不是
"明月\0\0\0\0"
如果我要用String来转换,完整的代码是这样的:

加上查找第一个零这一系列的动作后,这种方式就慢了。
同上,建议用 BenchmarkTools 测试,@time 只会计算一次的时间,误差大。
如果不修改数组,unsafe_string 比 String 更快。
data = rand(0x01:0xff, 20);
@btime unsafe_string(pointer(copy(data)))
# 59.017 ns (3 allocations: 144 bytes)
@btime String((copy(data)))
# 140.265 ns (2 allocations: 128 bytes)
如果允许清空数组,String 性能可以很高,比如
# 这里除了第一次运算,之后都是处理空集,所以看起来快了
@btime String($(copy(data)))
# 3.069 ns (0 allocations: 0 bytes)
纠正:unsafe_string 总比 String 更快,如果你有去 \0 的操作,前者更适合了。@linanisyugioh
这个我试了一下,它主要不是切片慢。是查找第一个零这个查找动作慢。
所以用@view的效果并不明显。