有人私信我说你们同元教程很烂(讲的太系统,不细节)
接下来我要忙着毕业的事情,代码肯定是不怎么碰了。
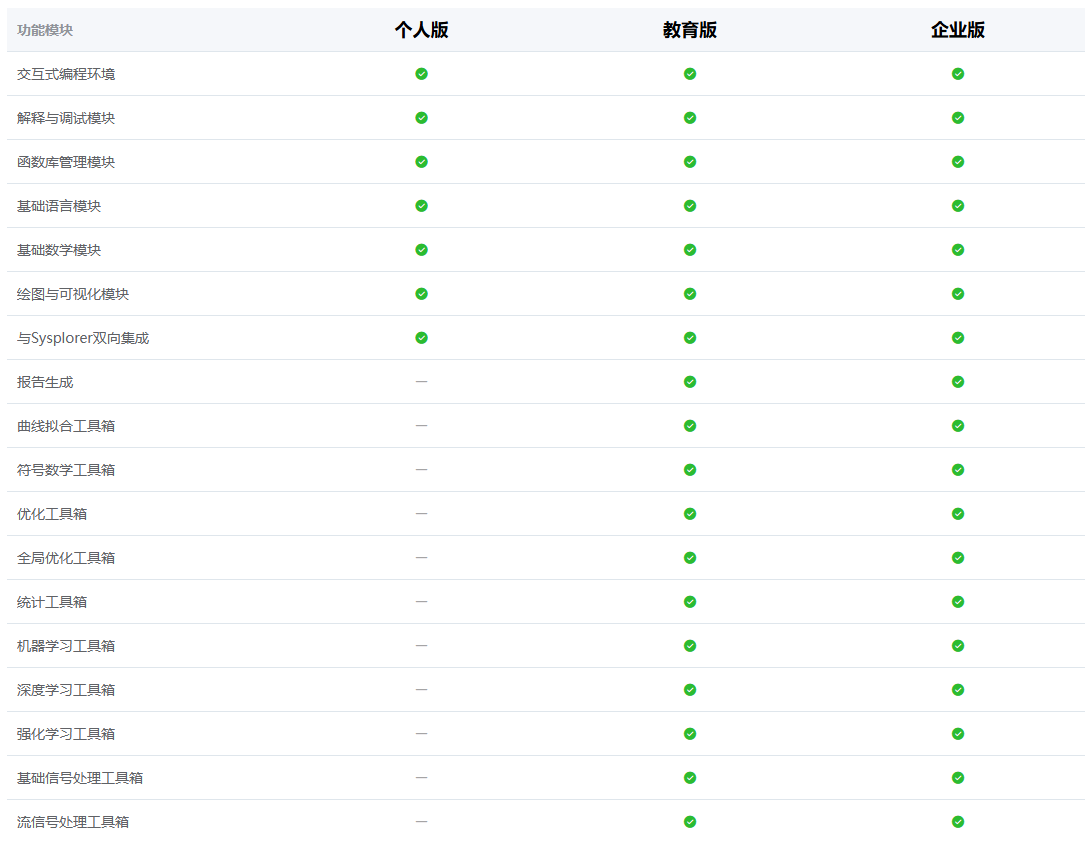
而且你们个人版曲线拟合、机器学习、深度学习包都不让用。你们要是对个人版多放开一点功能(或者送我个几年的个人授权),我工作以后用julia写代码玩,肯定用Syslab给你们推广 ![]() 。
。
我看过同元的视频,PPT是经过设计的。可是视频是未经修剪的、语气是比较平淡的,感觉像是看听不懂的学术会议的。
你们可以用下面的这个剪视频。
mli/autocut: 用文本编辑器剪视频 (github.com)
这个项目我记得本来是别人的,后来转给李沐了,反正李沐一直在用。
剪映也可以剪口播。但是它们(曾经)有个缺点:不能对每个单独口播片段调整时间范围——比如做教程时,你可能会等终端跳出结果,愣了一秒再讲话。所以需要能调整每个片段的时间范围。而且(曾经)whisper会有漏听的情况。
所以我自己写了个垃圾的(我很少读别人代码,所以代码烂):
XuJingye2022/VoiceVideoCut (github.com)
这个的大概逻辑是:
- 用麦克风音轨的音量大小初筛讲话片段,避免AI漏掉讲话内容(真的会漏掉,我确定);
- 手动决定保留哪些片段——比如可能有咳嗽在内;
- 每个讲话片段,向前拓展
a秒,向后拓展b秒,再组合。原本是处理游戏录屏,想偷懒,前后分别留下观众反应时间——比如看到了什么,我鬼叫了一下,前面留5秒的空挡可能会很不错。做教程可能可以短点,0.5秒之类。 - 组合后的片段预览,决定要不要。
- 剪辑。我按这个流程来处理游戏录屏,切掉了大部分我不讲话的片段,时长基本可以压缩一半。
创意和代码,只要你们不嫌烂,都可以拿走。