最近刚刚开始学习flux编写神经网络,按照flux官方文档自己写了一个拟合y=1-x的神经网络如下:
using Flux, CUDA, Statistics, ProgressMeter
using GLMakie
## 超参数定义
n_state = 1 # 状态空间维度
n_action = 1 # 动作空间维度
n_reward = 1 # 奖励空间维度(一定是1,返回一个标量)
n_hidden = 128 # 隐藏层大小
## 创建状态价值神经网络
ValueNetwork = Chain(
Dense(n_state => n_hidden, relu; init=Flux.glorot_uniform),
BatchNorm(n_hidden), # 对每一层进行归一化,这对提升模型的泛用性和性能非常重要
Dense(n_hidden => n_hidden, relu; init=Flux.glorot_uniform),
BatchNorm(n_hidden),
Dense(n_hidden => n_reward; init=Flux.glorot_uniform),
)
## 先训练拟合一个简单线性函数作为测试
# 创建训练集
train_size = 101 # 训练集的大小
x_train = collect(range(0.0, 1.0, train_size))
x_train = reshape(x_train, (1, train_size))
y_train = 1 .- x_train
y_train
## 训练神经网络
epoches = 1000 # 定义训练次数
learning_rate = 0.005 # 定义学习率
# julia的损失函数似乎无法像pytorch那样单独提取出来
optim = Flux.setup(Flux.Adam(learning_rate), ValueNetwork) # 为模型定义优化器
for epoch in collect(1:epoches)
loss, grads = Flux.withgradient(ValueNetwork) do m
y_hat = ValueNetwork(x_train)
Flux.mse(y_hat, y_train) # 计算损失函数
end
if epoch%100 == 0
println(loss)
end
Flux.update!(optim, ValueNetwork, grads[1]) # 训练神经网络
end
但是这个代码在训练的过程中似乎并没有执行梯度下降,我每训练100次打印一下loss,这是训练过程中loss的打印结果:
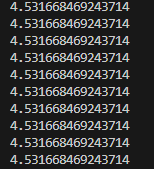
没有任何变化。感觉自己和官方文档写的差不多呀,不知道哪里有问题,求问 ![]()