用md贴代码,别贴图片
怎么还是你,好像发了三个帖子了,记得删一下 ![]() ,
,
顺便贴一下代码运行时间
@time your_code
这是你的代码,不过这个代码是拿来干什么的?
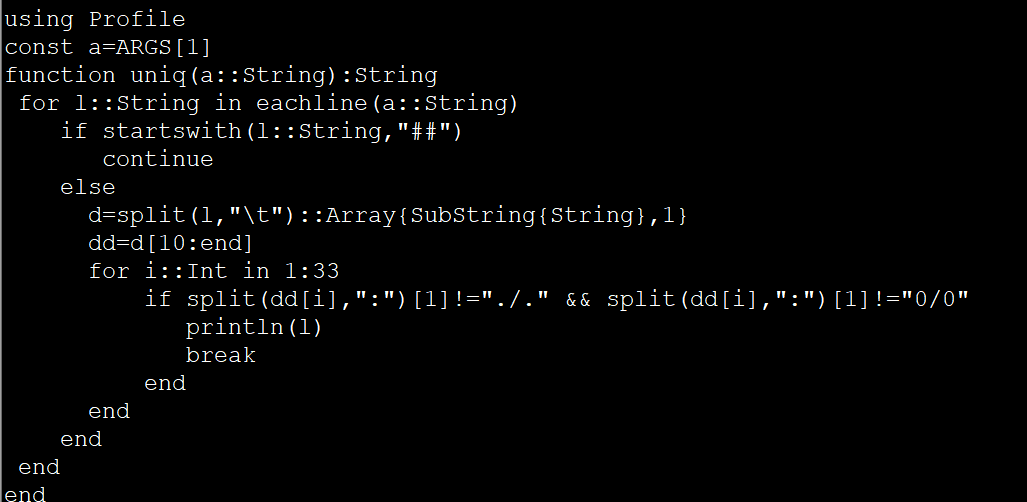
const a=ARGS[1]
function uniq(a::String):String
for l::String in eachline(a::String)
if startswith(l::String,"##")
continue
else
d=split(l,"\t")::Array{SubString{String},1}
dd=d[10:end]
for i::Int in 1:33
if split(dd[i],":")[1]!="./." && split(dd[i],":")[1]!=“0/0”
println(l)
break
end
end
end
end
end
uniq(a)
python 运行需要19min,julia30min,go只需要10min,测试显示 nextind_str 性能最大,但是不知该如何优化
有一个30G的文本文件,筛选其中的符合条件的行
需求详细一点吧,这样可能有热心的人帮你修改代码
有一个txt文件,33列,2000万行,根据每行第10 列到33列的内容筛选文件,如果第10列及之后的列,有不是0/0或./.开头的,就输出这一行。python代码用的就是Julia代码的简单翻译,但是奇怪的是Julia比python还慢
给我这个文件的部分内容,我测试一下,你看看正不正确
33列?是每行33个字吗
Chr7 186172875 Chr7__186172875 T C 27572.2 PASS AC=161;AF=0.958;AN=168;BaseQRankSum=-4.700e-01;ClippingRankSum=0.259;DP=1023;ExcessHet=3.5752;FS=3.104;InbreedingCoeff=-0.0514;MLEAC=161;MLEAF=0.958;MQ=58.99;MQRankSum=0.00;QD=31.28;ReadPosRankSum=-4.670e-01;SNPEFF_EFFECT=INTERGENIC;SNPEFF_IMPACT=MODIFIER;SNPEFF_FUNCTIONAL_CLASS=NONE;SOR=1.537 GT:AD:DP:GQ:PGT:PID:PL 1/1:0,8:8:24:.:.:334,24,0 1/1:0,7:7:21:.:.:258,21,0 1/1:0,7:7:21:.:.:246,21,0 1/1:0,10:10:30:.:.:300,30,0 1/1:0,18:18:54:.:.:627,54,0 0/1:2,5:7:28:.:.:130,0,28 1/1:0,6:6:18:.:.:251,18,0 1/1:0,3:3:9:.:.:113,9,0 1/1:0,6:6:18:.:.:247,18,0 1/1:0,12:12:36:.:.:418,36,0 1/1:0,8:8:24:.:.:333,24,0 1/1:0,5:5:15:.:.:163,15,0 1/1:0,9:9:27:.:.:342,27,0 1/1:0,8:8:24:.:.:288,24,0 1/1:0,10:10:30:.:.:400,30,0 1/1:0,6:6:21:.:.:214,21,0 1/1:0,7:7:21:.:.:280,21,0 1/1:0,8:8:24:.:.:300,24,0 1/1:0,12:12:36:.:.:382,36,0 1/1:0,6:6:18:.:.:238,18,0 1/1:0,10:10:30:.:.:418,30,0 1/1:0,15:15:45:1|1:186172855_T_G:565,45,0 1/1:0,11:11:33:.:.:425,33,0 1/1:0,15:15:45:.:.:541,45,0 1/1:0,12:12:36:.:.:451,36,0 1/1:0,19:19:57:.:.:657,57,0 1/1:0,10:10:30:.:.:349,30,0 1/1:0,6:6:18:.:.:217,18,0 1/1:0,4:4:12:.:.:167,12,0 1/1:0,13:13:39:.:.:459,39,0 1/1:0,5:5:15:.:.:209,15,0 1/1:0,10:10:30:.:.:362,30,0 1/1:0,11:11:33:.:.:391,33,0

切一点传给我吧
steiner3044@163.com
你说的列应该不是指字数,而是每一行的单词数吧
好的,已经发送到您的邮箱
我不知道对不对
function uniq(path::String)
for line in eachline(path)
if startswith(line,"##") == false
datas = split(line,"\t")
fn1 = x->split(x,":")
split_words = map(fn1,datas[10:33])
fn2 = strs->strs[1] != "0/0" || strs[1] != "./."
if all(fn2,split_words)
println(line)
end
end
end
end
你好歹写个注释啊,为什么变量名取名这么随意?
您好,我是初学,您的代码有一些地方不懂,我想要的结果是,如果一行中,它的第10列后,有任何一列只要不是0/0开头或./.开头就输出,您给的代码好像没有实现这个目的,不过,大神啊,您这代码太就快了速度,跪服,不知可否再修改一下,满足上述的需求呢,是否改用&&?
你说的或呀,应该没错,用||,可是我的代码还有点问题
do it again
function uniq(path::String)
for line in eachline(path)
if startswith(line,"##") == false
datas = split(line,"\t")
fn1 = x->split(x,":")
split_words = map(fn1,datas[10:33])
fn2 = strs-> begin
if strs[1] != "0/0" && strs[1] != "./."
println(strs)
end
end
map(fn2,split_words)
end
break
end
end
这个break可以拿掉,只是用来调试的
能不能用 md 把数据的一部分贴出来,我也想看一下 ![]()
这是第一部分数据的第11-33列
julia> datas
24-element Array{SubString{String},1}:
"0/1:7,1,0:8:21:0|1:1441_T_TA:21,0,320,42,323,365"
"0/1:8,1,0:9:18:0|1:1441_T_TA:18,0,354,42,357,399"
"0/0:19,0,0:19:48:.:.:0,48,720,48,720,720"
"0/0:15,1,0:16:3:0|1:1441_T_TA:0,3,610,45,613,655"
"0/0:15,0,0:15:33:.:.:0,33,495,33,495,495"
"0/2:5,0,6:11:99:.:.:129,144,281,0,137,120"
"0/0:16,0,0:16:33:.:.:0,33,495,33,495,495"
"0/2:11,5,8:24:84:.:.:154,84,418,0,166,317"
"0/2:13,0,3:16:44:.:.:44,83,507,0,424,415"
"0/0:16,0,0:16:27:.:.:0,27,405,27,405,405"
"0/0:8,0,0:8:18:.:.:0,18,270,18,270,270"
"0/0:5,0,0:5:15:.:.:0,15,197,15,197,197"
"0/1:3,2,0:5:75:0|1:1441_T_TA:75,0,105,84,111,195"
"0/0:12,0,0:12:21:.:.:0,21,315,21,315,315"
"0/0:12,0,0:12:18:.:.:0,18,270,18,270,270"
"0/1:3,5,0:8:66:.:.:121,0,66,130,81,211"
"0/0:8,0,0:8:15:.:.:0,15,225,15,225,225"
"./.:0,0,0:0:.:.:.:."
"./.:0,0,0:0:.:.:.:."
"0/0:4,0,0:4:6:.:.:0,6,90,6,90,90"
"0/0:8,0,0:8:12:.:.:0,12,180,12,180,180"
"0/0:6,0,0:6:12:.:.:0,12,180,12,180,180"
"./.:0,0,0:2:.:0|1:1431_A_G:."
"0/2:13,0,4:17:71:.:.:71,110,467,0,357,345"
这是第一部分数据
Chr1 1441 Chr1__1441 TA TAA,T 2048.89 PASS AC=14,10;AF=0.093,0.067;AN=150;BaseQRankSum=0.731;ClippingRankSum=0.731;DP=711;ExcessHet=13.7436;FS=0.000;InbreedingCoeff=-0.1815;MLEAC=14,10;MLEAF=0.093,0.067;MQ=50.00;MQRankSum=-5.730e-01;QD=10.40;ReadPosRankSum=0.747;SNPEFF_EFFECT=INTERGENIC;SNPEFF_IMPACT=MODIFIER;SNPEFF_FUNCTIONAL_CLASS=NONE;SOR=0.687;ANN=T|intergenic_region|MODIFIER|CHR_START-CSS0005497|CHR_START-CSS0005497|intergenic_region|CHR_START-CSS0005497|||n.1442delA||||||,TAA|intergenic_region|MODIFIER|CHR_START-CSS0005497|CHR_START-CSS0005497|intergenic_region|CHR_START-CSS0005497|||n.1442_1443insA|||||| GT:AD:DP:GQ:PGT:PID:PL 0/1:7,1,0:8:21:0|1:1441_T_TA:21,0,320,42,323,365 0/1:8,1,0:9:18:0|1:1441_T_TA:18,0,354,42,357,399 0/0:19,0,0:19:48:.:.:0,48,720,48,720,720 0/0:15,1,0:16:3:0|1:1441_T_TA:0,3,610,45,613,655 0/0:15,0,0:15:33:.:.:0,33,495,33,495,4950/2:5,0,6:11:99:.:.:129,144,281,0,137,120 0/0:16,0,0:16:33:.:.:0,33,495,33,495,495 0/2:11,5,8:24:84:.:.:154,84,418,0,166,317 0/2:13,0,3:16:44:.:.:44,83,507,0,424,415 0/0:16,0,0:16:27:.:.:0,27,405,27,405,405 0/0:8,0,0:8:18:.:.:0,18,270,18,270,270 0/0:5,0,0:5:15:.:.:0,15,197,15,197,197 0/1:3,2,0:5:75:0|1:1441_T_TA:75,0,105,84,111,195 0/0:12,0,0:12:21:.:.:0,21,315,21,315,315 0/0:12,0,0:12:18:.:.:0,18,270,18,270,2700/1:3,5,0:8:66:.:.:121,0,66,130,81,211 0/0:8,0,0:8:15:.:.:0,15,225,15,225,225 ./.:0,0,0:0:.:.:.:. ./.:0,0,0:0:.:.:.:. 0/0:4,0,0:4:6:.:.:0,6,90,6,90,90 0/0:8,0,0:8:12:.:.:0,12,180,12,180,180 0/0:6,0,0:6:12:.:.:0,12,180,12,180,180 ./.:0,0,0:2:.:0|1:1431_A_G:. 0/2:13,0,4:17:71:.:.:71,110,467,0,357,345 0/0:4,0,0:4:6:.:.:0,6,90,6,90,90 0/2:6,0,3:9:65:.:.:65,83,248,0,165,156 0/0:7,0,0:8:21:0|1:1431_A_G:0,21,302,21,302,302 0/0:14,0,0:14:21:.:.:0,21,315,21,315,315 0/0:6,0,0:6:15:.:.:0,15,225,15,225,225 0/1:4,1,0:5:14:.:.:14,0,105,26,108,134
只要第[11:end] 存在不是 0/0和./.以为的值,就输出
大神的代码我还在看,不会改,虽然没实现的我的目的,但是给我很大启发,不然我都可能放弃Julia了
看来不是||,而是&& ,代码我又改了一遍,那个break可以拿掉
少用for,Julia支持函数式编程,多用高阶函数